在本教程中,你了解了如何使用Azure Functions触发批处理作业。 本文演示了一个示例,该示例采用添加到 Azure 存储 Blob 容器的文档,通过 Azure Batch 应用光学字符识别(OCR)。 为了简化 OCR 处理,此示例配置了 Azure 函数,该函数在每次将文件添加到 Blob 容器时都会运行批处理 OCR 作业。 学习如何:
- 使用 Azure 门户创建池和作业。
- 创建 Blob 容器和共享访问签名(SAS)。
- 创建 Blob 触发的 Azure 函数。
- 将输入文件上传到存储。
- 监视任务执行情况。
- 检索输出文件。
先决条件
登录 Azure
登录 Azure 门户。
使用 Azure 门户创建批处理池和批处理作业
在本部分中,你使用 Azure 门户创建运行 OCR 任务的批处理池和批处理作业。
创建池
使用 Azure 凭据登录到 Azure 门户。
选择左侧导航栏上的“池”以创建池,然后选择搜索窗体上方的“添加”按钮。
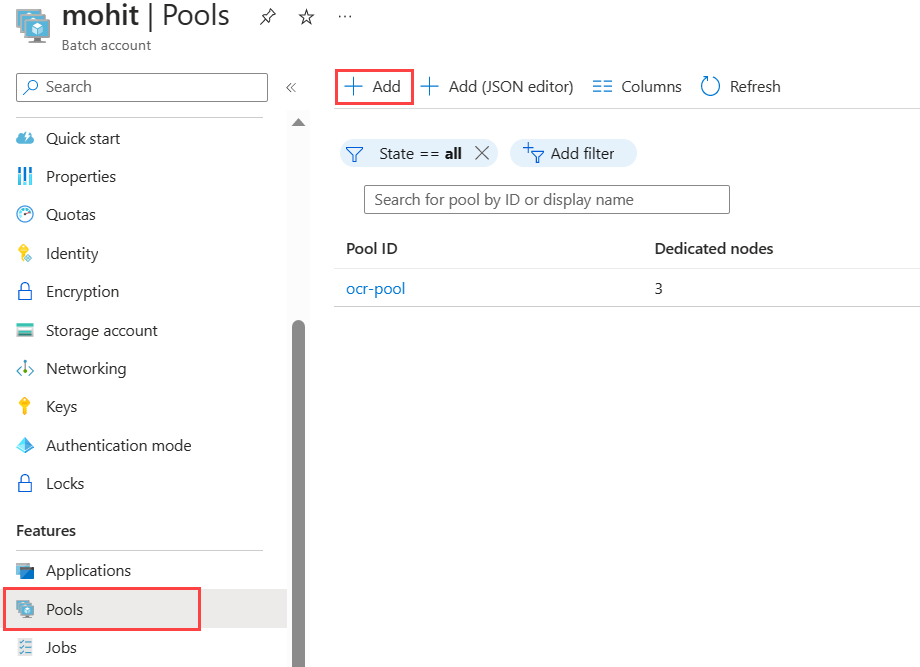
- 输入池 ID。 此示例将池命名为
ocr-pool。 - 选择“规范”作为发布服务器。
- 选择“0001-com-ubuntu-server-jammy”作为套餐。
- 选择“22_04-lts”作为SKU。
- 在“节点大小”部分选择
Standard_F2s_v2 - 2 vCPUs, 2 GB Memory作为“VM 大小”。 - 在“缩放”部分中,将“模式”设置为“固定”,并为“目标专用节点”输入 3。
- 将“启动任务”设置为“已启用”启动任务”,然后在“命令行”中输入命令
/bin/bash -c "sudo update-locale LC_ALL=C.UTF-8 LANG=C.UTF-8; sudo apt-get update; sudo apt-get -y install ocrmypdf"。 必须将“提升级别”设置为“池自动用户,管理员”,允许启动任务包含带有sudo的命令。 - 选择“确定” 。
- 输入池 ID。 此示例将池命名为
创建作业
- 选择左侧导航栏上的“作业”以在池上创建作业,然后选择搜索窗体上方的“添加”按钮。
- 输入作业 ID。 本示例使用
ocr-job。 - 为当前池选择
ocr-pool或为池选择的任何名称。 - 选择“确定”。
- 输入作业 ID。 本示例使用
创建 Blob 容器
此处会创建 Blob 容器,用于存储 OCR 批处理作业的输入和输出文件。 在本例中,输入容器命名为 input,所有未应用 OCR 的文档最初都会上传到输入容器进行处理。 输出容器名为 output,批处理作业将应用了 OCR 的处理过的文档写入输入容器。
在 Azure 门户中,搜索并选择“存储帐户”。
选择链接到批处理帐户的存储帐户。
从左侧导航栏中选择“容器”,并按照“创建 Blob 容器”中的步骤创建两个 Blob 容器(一个用于输入文件,一个用于输出文件)。
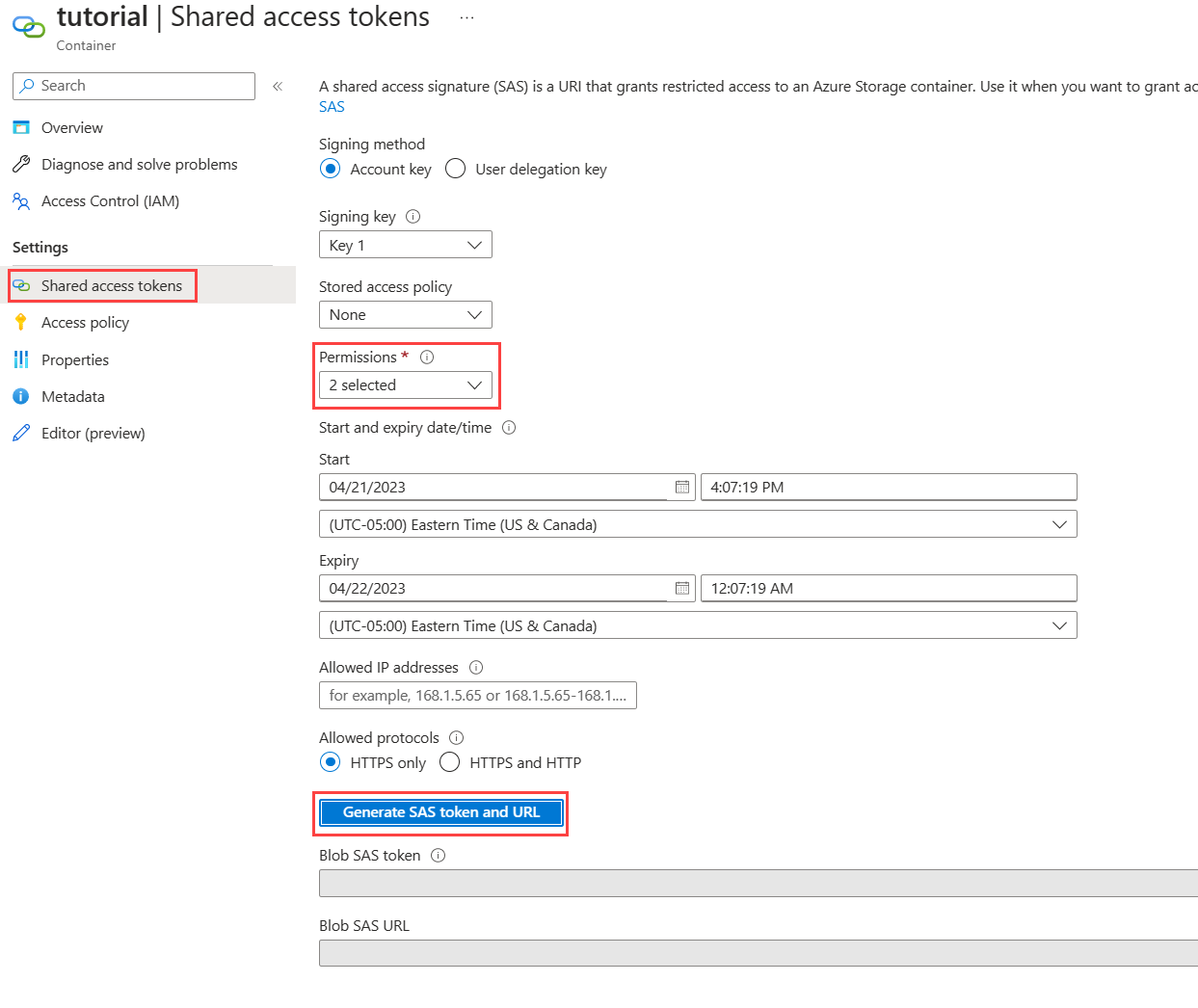
选择输出容器以为输出容器创建共享访问签名,然后在“共享访问令牌”页面的“权限”下拉列表中选择“写入”。 不需要其他权限。
选择“生成 SAS 令牌和 URL”,并复制“Blob SAS URL”以供稍后用于函数。
创建 Azure 函数
在本节中,你创建了 Azure 函数,每当文件上传到输入容器时,该函数都会触发 OCR 批处理作业。
按照创建由 Azure Blob 存储触发的函数中的步骤创建函数。
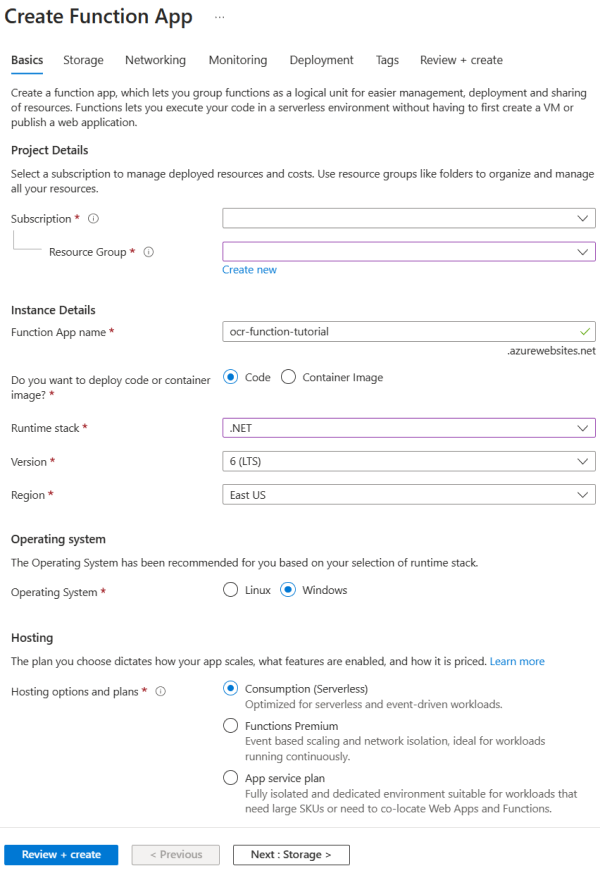
- 对于运行时堆栈,选择“.NET” 。 此示例函数使用 C# 来利用 Batch .NET SDK。
- 在“存储”页面,使用链接到批处理帐户的同一存储帐户。
- 选择“查看 + 创建>”创建。
以下屏幕截图是使用示例信息在“基本信息”选项卡上“创建函数应用”页面。
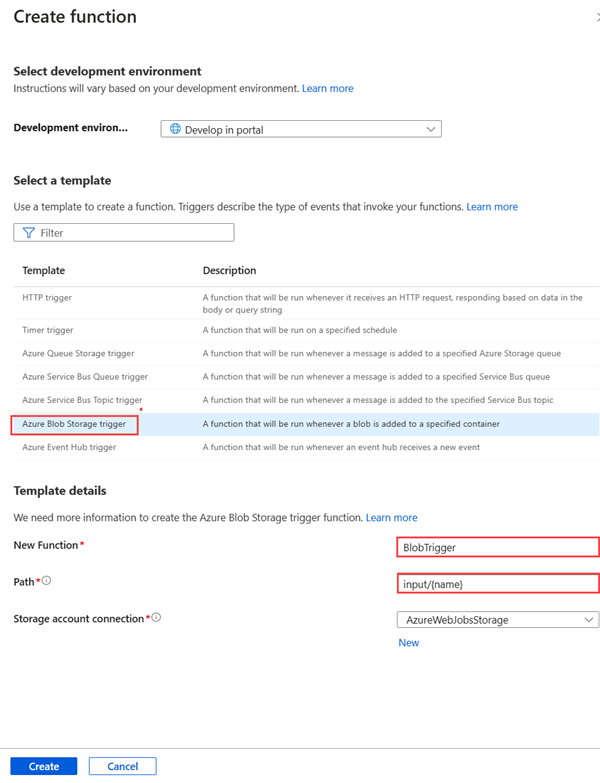
在函数中,从左侧导航栏中依次选择“函数”、“创建”。
在“创建函数”窗格中,选择“Azure Blob 存储触发器”。
在“新函数”中输入函数名称。 在此示例中,名称为 OcrTrigger。 输入路径作为
input/{name},其中输入 Blob 容器的名称。选择创建。
创建 blob 触发的函数后,选择“代码 + 测试”。 在函数中使用 GitHub 中的
run.csx和function.proj。 默认情况下function.proj不存在,因此请选择“上传”按钮将其上传到开发工作区。run.csx在将新 Blob 添加到输入 Blob 容器时运行。function.proj列出函数代码中的外部库(例如,批处理 .NET SDK)。
更改
run.csx文件的Run()函数中变量的占位符值,以反映批处理和存储凭据。 在“Azure 门户”的批处理和存储帐户的“密钥”部分,可以找到批处理和存储帐户凭据。


触发函数并检索结果
将 GitHub 上的 input_files 目录中的任何或所有扫描文件上传到输入容器。
可以从函数的“代码 + 测试”页面的 Azure 门户中测试函数。
- 在“代码 + 测试”页面,选择“测试/运行”。
- 在“输入”选项卡的“正文”中输入输入容器的路径。
- 选择“运行”。
几秒钟后,将应用了 OCR 的文件添加到输出容器中。 日志信息输出到底部窗口。 然后,该文件在存储资源管理器上可见并可检索。
或者,可以在“监视”页面找到日志信息:
2019-05-29T19:45:25.846 [Information] Creating job...
2019-05-29T19:45:25.847 [Information] Accessing input container <inputContainer>...
2019-05-29T19:45:25.847 [Information] Adding <fileName> as a resource file...
2019-05-29T19:45:25.848 [Information] Name of output text file: <outputTxtFile>
2019-05-29T19:45:25.848 [Information] Name of output PDF file: <outputPdfFile>
2019-05-29T19:45:26.200 [Information] Adding OCR task <taskID> for <fileName> <size of fileName>...
要将输出文件下载到本地计算机,请转到存储帐户中的输出容器。 在所需文件上选择更多选项,然后选择“下载”。
提示
如果在 PDF 阅读器中打开下载的文件,则可以对其进行搜索。
清理资源
只要有节点在运行,就会对池收费,即使没有计划作业。 不再需要池时,请通过以下步骤将其删除:
- 在批处理帐户的“池”页面,在池上选择更多选项。
- 选择“删除”。
删除池时会删除节点上的所有任务输出。 但是,输出文件保留在存储帐户中。 当不再需要时,还可以删除 Batch 帐户和存储帐户。
后续步骤
如需更多示例,以便了解如何使用 .NET API 来计划和处理 Batch 工作负荷,请参阅 GitHub 上的示例。