Azure SQL 托管实例的高可用性
适用于:![]() Azure SQL 托管实例
Azure SQL 托管实例
本文介绍 Azure SQL 托管实例中的高可用性。
概述
Azure SQL 托管实例中高可用性体系结构的目标是最大程度地减少客户发起的管理操作(这些操作会导致短暂停机、服务维护操作和计划外中断)对客户工作负载的影响。 有关不同服务层的特定 SLA 的详细信息,请查看 Azure SQL 托管实例。
高可用性可保护你免受以下情况的影响:
- 为服务提供支持之节点所运行的机架
- 节点本身
- 应用层
为了最大程度地减少区域范围或更大范围的中断所造成的影响,可使用业务连续性概述中所述的可用技术。
SQL 托管实例在 Windows 操作系统上稳定的最新版 SQL Server 数据库引擎上运行,其中包含所有适用的修补程序。 SQL 托管实例会自动处理关键的维护任务(例如修补、备份、Windows 和 SQL 引擎升级),以及底层硬件故障、软件故障或网络故障等计划外事件。 实例得到修补或进行故障转移时,如果在应用中使用重试逻辑,则停机通常不会产生影响。 即使出现最严重的问题,SQL 托管实例也能快速恢复,确保数据始终可用。 大多数用户不会注意到升级是持续执行的。
高可用性解决方案旨在确保提交的数据永远不会由于故障而丢失,维护操作不会影响工作负荷,且实例不会成为软件体系结构中的单一故障点。
有两种不同的基于服务层级的高可用性体系结构模型:
- 基于“常规用途”服务层级中的计算和存储隔离的远程存储模型,该模型依赖于远程存储的高可用性和可靠性以及由 Azure Service Fabric 管理的计算群集的高可用性。 此高可用性模型面向可以容忍在维护活动期间出现一定程度的性能下降的预算导向型业务应用程序。
- 基于数据库引擎进程群集的本地存储模型,该模型依赖于“业务关键”服务层级中具有本地存储的可用数据库引擎节点的仲裁。 此本地存储模型面向具有较高事务处理率且需要较高 IO 性能的任务关键型应用程序。 此高可用性体系结构保证维护活动期间尽量减小对工作负载性能造成的影响。
本地冗余可用性
本地冗余可用性基于将计算节点和数据存储在主要区域的单个数据中心内,并在发生本地故障(例如小规模网络或电源故障)时保护数据。 如果区域内发生火灾或洪水等大规模灾难,则存储帐户的所有副本或计算节点上的数据可能会丢失或无法恢复。 因此,为了在使用本地冗余可用性选项时进一步保护数据,请考虑为数据库备份使用更具弹性的存储选项。
“常规用途”服务层级
常规用途服务层级使用远程存储可用性体系结构。 下图显示了具有隔离的计算和存储层的四个不同节点。
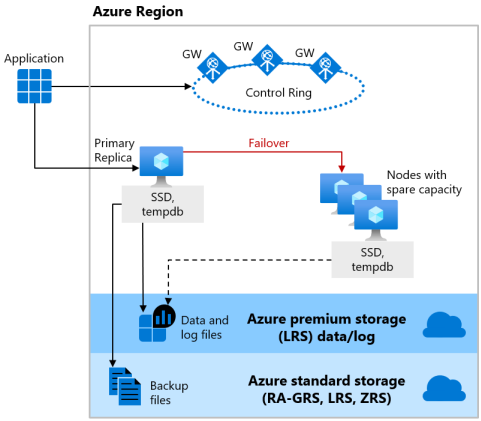
远程存储可用性模型包括两个层:
- 无状态计算层:运行数据库引擎进程,仅包含暂时性的缓存数据,例如在附加的 SSD 上的
tempdb和model数据库,内存中的计划缓存、缓冲池和列存储池。 此无状态节点由 Azure Service Fabric 运行。后者会初始化数据库引擎、控制节点运行状况,并根据需要执行到另一节点的故障转移。 - 有状态数据层,包含存储在 Azure Blob 存储中的数据库文件(
.mdf和.ldf)。 Azure Blob 存储具有内置的数据可用性和冗余功能。 本地冗余可用性基于将数据存储在本地冗余存储 (LRS) 中,该存储在主要区域的单个数据中心内复制数据三次。 它可以保证即使数据库引擎进程崩溃,日志文件中的每条记录或者数据文件中的页面也仍会得到保留。
每当升级数据库引擎或操作系统,或者检测到故障时,Azure Service Fabric 会将无状态数据库引擎进程移到具有足够可用容量的另一个无状态计算节点。 Azure Blob 存储中的数据不受移动操作的影响,数据/日志文件将附加到新初始化的数据库引擎进程。 此过程保证高可用性,但在过渡期间,繁重工作负载的性能可能会有一定程度的下降,因为新的数据库引擎进程是使用冷缓存启动的。
“业务关键”服务层级
业务关键型服务层级利用本地存储可用性模型,该模型与单个节点上的计算资源(数据库引擎进程)和存储(本地附加的 SSD)相集成。 实现高可用性的方式是将计算和存储资源复制到其他节点。
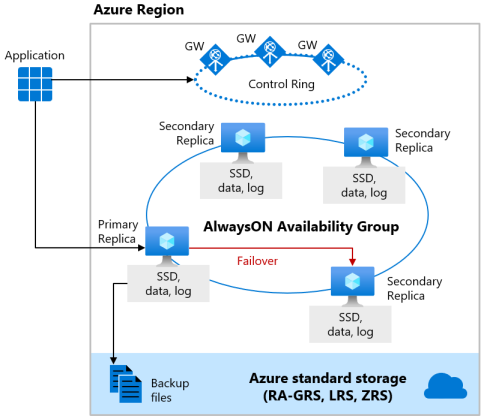
底层数据库文件 (.mdf/.ldf) 放在附加的 SSD 存储中,以便为工作负荷提供延迟极低的 IO。 高可用性是使用类似于 SQL Server Always On 可用性组的技术来实现的。 群集包含可供读/写客户工作负载访问的单个主要副本,最多包含三个次要副本(计算和存储),这些副本包含数据的副本。 主要副本不断地将更改按顺序推送到次要副本,在提交每个事务之前,它可确保数据保留到足够数量的次要副本上。 此过程可以保证,当主要副本或可读次要副本因任何原因不可用时,始终可以故障转移到某个完全同步的副本。 故障转移由 Azure Service Fabric 启动。 次要副本成为新的主要副本后,将创建另一个次要副本,以确保群集具有足够数量的副本来维护仲裁。 故障转移完成后,Azure SQL 连接会根据连接字符串自动重定向到新的主要副本(或可读次要副本)。
作为一项额外的优势,本地存储可用性模型提供用于将只读 Azure SQL 连接重定向到某个次要副本的功能。 此功能称为读取扩展。它通过主要副本免费提供 100% 的额外计算容量,以减轻分析工作负荷等只读操作的负担。
测试应用程序的故障复原能力
可用性是 SQL 托管实例平台的基本功能,其运作对数据库应用程序透明。 不过,我们认识到,你可能需要先测试在计划内或计划外事件期间启动的自动故障转移操作对应用程序的具体影响,然后才会将其部署到生产环境。 可以通过调用特殊的 API 来重启托管实例,从而手动触发故障转移。 由于重启操作会干扰系统,其数量过多可能会对平台造成压力,因此每个托管实例每 15 分钟只允许进行一次故障转移调用。
在真正的故障转移期间,与实例的连接会失败,而 SQL 服务在不同的节点上成为主服务。 若要模拟故障转移,请调用重启 SQL 进程的命令以模拟启动服务的过程,就好像发生了故障转移一样。 但是,与模拟故障转移相比,在真正的故障转移期间,连接失败的时间可能会更长,因为在真正的故障转移期间,SQL 进程会成为群集中另一个虚拟机的主进程,而在模拟故障转移期间,SQL 进程会在现有虚拟机上重新启动。
本节中的手动故障转移命令通常仅在本地重新启动 SQL 进程,而不会启动到另一个节点的故障转移,但有一些例外情况。 此本地故障转移与针对故障转移组发生的故障转移不同。
可以使用 PowerShell、REST API 或 Azure CLI 启动本地故障转移:
| PowerShell | REST API | Azure CLI |
|---|---|---|
| Invoke-AzSqlInstanceFailover | SQL 托管实例 - 故障转移 | az sql mi failover 可用于从 Azure CLI 调用 REST API 调用 |
结论
Azure SQL 托管实例提供与 Azure 平台深度集成的内置高可用性解决方案。 该服务依赖于 Service Fabric 以检测故障和恢复,并依赖于 Azure Blob 存储以保护数据。 对于“业务关键”服务层级,SQL 托管实例使用 SQL Server 的 Always On 可用性组技术来执行数据库复制和故障转移。 将这些技术相结合,应用程序可完全实现混合存储模型的优势并支持最严格的 SLA。
后续步骤
- 了解 Service Fabric
- 了解 Azure 流量管理器
- 了解如何在 SQL 托管实例上发起手动故障转移
- 有关高可用性和灾难恢复的更多选项,请参阅业务连续性