适用于:![]() Azure SQL 托管实例
Azure SQL 托管实例
本文介绍了如何在 Azure SQL 托管实例中监视和管理数据库中的文件。 我们会了解如何监视数据库文件大小、收缩事务日志、放大事务日志文件,以及控制事务日志文件的增长。
本文适用于 Azure SQL 托管实例。 虽然非常相似,但有关在 SQL Server 中管理事务日志文件大小的信息,请参阅管理事务日志文件的大小。
了解数据库存储空间的类型
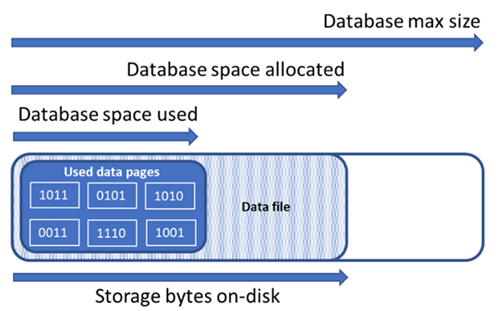
了解以下存储空间数量对于管理数据库的文件空间非常重要。
| 数据库数量 | 定义 | 注释 |
|---|---|---|
| 已用数据空间 | 用于存储数据库数据的空间量。 | 通常,已用空间会在执行插入操作时增大,在执行删除操作时减小。 在某些情况下,已用空间不会在执行插入或删除操作时发生变化,具体取决于该操作涉及的数据数量和模式,以及是否有任何碎片。 例如,从每个数据页中删除一行不一定会减小已用空间。 |
| 已分配的数据空间 | 可用于存储数据库数据的格式化文件空间量。 | 已分配的空间量会自动增长,但执行删除操作后永远不会减小。 此行为可确保将来的插入操作速度更快,因为不需要重新设置空间的格式。 |
| 已分配但未使用的数据空间 | 已分配的数据空间量与已使用的数据空间量之间的差值。 | 此数量表示通过收缩数据库数据文件可回收的最大可用空间量。 |
| 数据最大大小 | 可用于存储数据库数据的最大空间量。 | 已分配的数据空间量在增长后不能超过数据最大大小。 |
下图演示了数据库的不同存储空间类型之间的关系。
查询单一数据库的文件空间信息
使用以下查询 sys.database_files,返回已分配的以及已分配但未使用的数据库文件空间量。 查询结果以 MB 为单位。
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
监视日志空间使用情况
使用 sys.dm_db_log_space_usage 监视日志空间使用情况。 此 DMV 返回有关当前使用的日志空间量信息,并指示何时需要截断事务日志。
若要了解有关日志文件的当前大小、最大大小以及文件的自动增长选项的信息,还可以在sys.database_files中针对此日志文件使用size、max_size、growth列。
基于 Azure 资源管理器的指标以下 API 中显示的存储空间指标仅度量已用数据页面的大小。 有关示例,请参阅 PowerShell get-metrics。
收缩日志文件大小
要通过删除未使用的空间来减少物理日志文件的物理大小,必须收缩日志文件。 只有当事务日志文件包含未使用的空间时,收缩才会产生影响。 如果日志文件已满(可能是由于打开的事务),请调查 什么正在阻止事务日志截断。
注意
收缩操作不应被视为常规维护操作。 由于常规定期业务操作而增长的数据和日志文件不需要收缩操作。 Shrink 命令在运行时可能会影响数据库的性能,请尽量在使用率较低的时候运行它。 如果常规应用程序工作负载会导致文件再次增长到相同的分配大小,则不建议收缩数据文件。
注意收缩数据库文件的潜在负面影响,请参阅收缩后索引维护。 在极少数情况下,收缩操作可能会受到自动数据库备份的影响。 如有必要,请重试收缩操作。
收缩事务日志前,请记住可能延迟日志截断的因素。 如果在日志收缩后还需要存储空间,则会再次增加事务日志,导致在增加日志操作期间产生性能开销。 有关详细信息,请参阅建议。
仅当数据库处于联机状态,而且至少一个虚拟日志文件 (VLF) 可用时,才能收缩日志文件。 在某些情况下,直到下一个日志截断后,才能收缩日志。
能够延长VLF活动时间的因素(如长时间运行的事务)可以限制甚至阻止日志收缩。 有关详细信息,请参阅可能延迟日志截断的因素。
收缩日志文件可删除一个或多个不包含逻辑日志任何部分的 VLF(即不活动的 VLF)。 收缩事务日志文件时,将从日志文件末端删除不活动的 VLF,以将日志减小到接近目标大小。
有关收缩操作的详细信息,请查看以下内容:
收缩日志文件(而不收缩数据库文件)
监视日志文件收缩事件
监视日志空间
sys.database_files (Transact-SQL)(请参阅日志文件或文件的
size、max_size和growth列。)
收缩后的索引维护
对数据文件执行完收缩操作后,索引可能会变得碎片化。 这会使某些工作负载的性能优化不再有效,例如使用大型扫描进行的查询。 如果在收缩操作完成后性能下降,请考虑通过索引维护来重新生成索引。 请记住,重新生成索引需要使用数据库中的可用空间,因此可能会导致已分配的空间增加,从而抵消收缩的影响。
有关索引维护的详细信息,请参阅优化索引维护以提高查询性能并减少资源消耗。
评估索引页密度
如果截断数据文件未导致分配的空间的充分减少,可以决定收缩数据库数据文件,以从这些文件回收未使用的空间。 但是,作为可选但建议的步骤,应首先确定数据库中索引的平均页面密度。 对于相同数量的数据,如果页面密度较高,收缩将更快完成,因为它只需移动更少的页面。 如果某些索引的页面密度较低,请考虑对这些索引执行维护,以增加页面密度,然后再收缩数据文件。 这也将使收缩可以进一步减少分配的存储空间。
若要确定数据库中所有索引的页面密度,请使用以下查询。 页面密度在 avg_page_space_used_in_percent 列中报告。
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
如果存在页数较多且页密度低于 60-70% 的索引,请考虑在收缩数据文件之前重新生成或重新组织这些索引。
注意
对于较大的数据库,用于确定页面密度的查询可能需要很长时间(数小时)才能完成。 此外,重新生成或重新组织大型索引也需要大量时间和资源使用。 一方面是花费额外的时间增加页面密度,另一方面是减少收缩持续时间和节省更多空间,这两者之间存在着一种权衡。
如果有多个索引的页面密度较低,可以在多个数据库会话中并行重新生成它们,以加快该过程。 但是,请确保这样做不会接近数据库资源限制,并为应用程序工作负载留出足够的资源空余空间。 在 Azure 门户中或使用 sys.dm_db_resource_stats 视图监视资源消耗(CPU、数据 IO、日志 IO),并且仅当上述每个维度上的资源利用率一直远低于 100% 时才启动其他并行重新生成。 如果 CPU、数据 IO 或日志 IO 利用率为 100%,则可以纵向扩展数据库,以拥有更多 CPU 核心并增加 IO 吞吐量,从而允许额外的并行重建以更快地完成该过程。
示例索引重新生成命令
下面是使用 ALTER INDEX 语句重新生成索引并增加其页面密度的示例命令:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
此命令将启动联机的可恢复索引重新生成。 这样,并发工作负载可以在重新生成过程中继续使用表,你可以在重新生成因任何原因中断后继续重新生成。 但是,这种类型的重新生成比脱机重新生成慢,后者会阻止对表的访问。 如果在重新生成期间没有其他工作负载需要访问表,请将 ONLINE 和 RESUMABLE 选项设置为 OFF 并删除 WAIT_AT_LOW_PRIORITY 子句。
若要了解有关索引维护的详细信息,请参阅优化索引维护以提高查询性能并减少资源消耗。
收缩多个数据文件
如前所述,通过数据移动进行收缩是一个长时间运行的过程。 如果数据库有多个数据文件,可以通过并行收缩多个数据文件来加快该过程。 为此,可以打开多个数据库会话,并在每个会话中使用具有不同 file_id 值的 DBCC SHRINKFILE。 与前面重新生成索引类似,在开始每个新的并行收缩命令之前,请确保你有足够的资源空余空间(CPU、数据 IO、日志 IO)。
以下示例命令通过使用file_id 4 文件,移动文件中的页面来收缩数据文件,尝试将分配的大小缩小到 52,000 MB:
DBCC SHRINKFILE (4, 52000);
如果想将分配给文件的空间缩小到最小,请执行以下语句而不指定目标大小:
DBCC SHRINKFILE (4);
如果工作负载与收缩同时运行,它可能会在收缩完成并截断文件之前开始使用收缩释放的存储空间。 在这种情况下,收缩将无法将已分配的空间缩小到指定的目标。
可以通过以较小的跨度收缩每个文件来缓解这种情况。 这意味着,在DBCC SHRINKFILE命令中,设置的目标略小于文件当前分配的空间。 例如,如果为 file_id 为 4 的文件分配的空间是 200,000 MB,并且要将其缩小到 100,000 MB,则可以先将目标设置为 170,000 MB:
DBCC SHRINKFILE (4, 170000);
此命令完成后,它将截断文件,并将其分配大小减小到 170,000 MB。 然后可以重复此命令,先将目标设置为 140,000 MB,然后设置为 110,000 MB,依此类推,直到文件缩小到所需的大小。 如果命令完成但文件未截断,请使用更小的跨度,例如 15,000 MB 而不是 30,000 MB。
若要监视所有并发运行的收缩会话的收缩进度,可以使用以下查询:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
注意
收缩进度可能是非线性的,并且 percent_complete 列中的值可能在很长一段时间内几乎保持不变,即使收缩仍在进行中。
完成所有数据文件的收缩后,请使用空间使用情况查询确定分配的存储大小的最终减少量。 如果已用空间和分配的空间之间仍有较大差异,则可以重新生成索引。 这可能会暂时进一步增加分配的空间,但是在重新生成索引后再次收缩数据文件,应会使分配的空间进一步减小。
放大日志文件
在 Azure SQL 托管实例中,放大现有日志文件(如果磁盘空间允许)以将空间添加到日志文件。 不支持将日志文件添加到数据库。 一个事务日志文件就足够了,除非日志空间不足且保留日志文件的卷上的磁盘空间也不足。
要扩大日志文件,请使用 ALTER DATABASE 语句的 MODIFY FILE 子句,指定 SIZE 和 MAXSIZE 语法。 有关详细信息,请参阅 ALTER DATABASE (Transact-SQL) 文件和文件组选项。
有关详细信息,请参阅建议。
控制事务日志文件的增长
使用 ALTER DATABASE (Transact-SQL) 文件和文件组选项语句管理事务日志文件的增长。 请注意以下事项:
- 要更改当前文件大小(以 KB、MB、GB 和 TB 为单位),请使用
SIZE选项。 - 要更改增量,请使用
FILEGROWTH选项。 如果值为 0,则表明自动增长已设置为关闭,且不允许增加空间。 - 要控制日志文件的最大大小(以 KB、MB、GB 和 TB 为单位)或将增长设置为 UNLIMITED,请使用
MAXSIZE选项。
建议
下面是使用事务日志文件时的一些一般建议:
FILEGROWTH选项设置的事务日志的自动增长 (autogrow) 增量必须足够大,以领先于工作负载事务的需求。 因此,为了避免经常向日志文件中扩充内容,应该采用足够大的文件增量。 要正确设置事务日志的大小,建议监视以下时间内所占用的日志数量:- 执行完整备份所需的时间,因为日志备份在其完成后才能进行。
- 最大型索引维护操作所需的时间。
- 在数据库中执行最大批操作所需的时间。
使用
FILEGROWTH选项设置数据和日志文件的autogrow时,建议首选使用size而不是使用percentage进行设置,以便更好地控制增长比,因为 percentage 表示的是日益增长量。- 在 Azure SQL 托管实例中,即时文件初始化可能会使事务日志增长事件受益高达 64 MB。 新数据库的默认自动增长大小增量为 64 MB。 大于 64 MB 的事务日志文件自动增长事件则无法利用即时文件初始化。
- 最佳做法是,针对日志事务,请勿将
FILEGROWTH选项值设置为超过 1,024 MB。
小型的自动增长增量可能生成过多的VLF并且可能降低性能。 若要确定给定实例中所有数据库的当前事务日志大小的最佳 VLF 分发,以及实现所需大小需要的增长量,请参阅此脚本以分析和修复 VDF(由 SQL Tiger Team 提供)。
大型自动增长增量可能会导致两个问题:
- 大型自动增长增量可能会导致数据库在分配新空间时暂停,这可能会导致查询超时。
- 大型的自动增长增量可能生成过少的大型VLF并且也可能影响性能。 若要确定给定实例中所有数据库的当前事务日志大小的最佳 VLF 分发,以及实现所需大小需要的增长量,请参阅此脚本以分析和修复 VDF(由 SQL Tiger Team 提供)。
即使启用自动增长,如果增长速度不能满足查询需求,也可能收到提示事务日志已满的消息。 有关更改增长增量的详细信息,请参阅ALTER DATABASE (Transact-SQL) 文件和文件组选项。
日志文件可以设为自动收缩。 但是,不建议这样做,auto_shrink 数据库属性默认设为 FALSE。 如果 auto_shrink 设置为 TRUE,则仅当其空间的 25% 以上未使用时,自动收缩才会减少文件的大小。
- 文件将收缩至未使用空间占文件 25% 的大小,或者收缩至文件的原始大小,以两者中较大者为准。
- 有关更改 auto_shrink 属性设置的详细信息,请参阅查看或更改数据库的属性和 ALTER DATABASE SET 选项 (Transact-SQL)。