Azure Functions Python 开发人员指南
本指南介绍如何使用 Python 开发 Azure Functions。 本文假设你已阅读 Azure Functions 开发人员指南。
重要
本文支持 Azure Functions 中 Python 的 v1 和 v2 编程模型。 Python v1 模型使用 functions.json 文件来定义函数,而新的 v2 模型允许改用基于修饰器的方法。 这种新方法可以简化文件结构,并更注重代码。 请选择文章顶部的“v2”选择器来了解这种新的编程模型。
作为 Python 开发人员,你可能还对以下主题感兴趣:
- Visual Studio Code:使用 Visual Studio Code 创建你的第一个 Python 应用。
- 终端或命令提示符:使用 Azure Functions Core Tools 从命令提示符创建你的第一个 Python 应用。
- 示例:在 Learn 示例浏览器中查看一些现有的 Python 应用。
- Visual Studio Code:使用 Visual Studio Code 创建你的第一个 Python 应用。
- 终端或命令提示符:使用 Azure Functions Core Tools 从命令提示符创建你的第一个 Python 应用。
- 示例:在 Learn 示例浏览器中查看一些现有的 Python 应用。
开发选项
这两个 Python 函数编程模型都支持在以下任一环境中进行本地开发:
Python v2 编程模型:
Python v1 编程模型:
此外,还可以在 Azure 门户中创建 Python v1 函数。
提示
尽管可以在 Windows 上本地开发基于 Python 的 Azure Functions,但仅在 Azure 中运行时,基于 Linux 的托管计划才支持 Python。 有关详细信息,请参阅支持的操作系统/运行时组合列表。
编程模型
Azure Functions 要求函数是 Python 脚本中处理输入并生成输出的无状态方法。 默认情况下,运行时预期该方法在 __init__.py 文件中作为名为 main() 的全局方法实现。 还可以指定替代入口点。
来自触发器和绑定的数据使用在 function.json 文件中定义的 name 属性,通过方法特性绑定到函数。 例如,以下 function.json 文件描述一个由名为 req 的 HTTP 请求触发的简单函数:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
根据这一定义,包含函数代码的 __init__.py 文件可能类似于以下示例:
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
还可以使用 Python 类型注释在函数中显式声明属性类型和返回类型。 此操作有助于使用许多 Python 代码编辑器提供的 IntelliSense 和自动完成功能。
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
使用 azure.functions.* 包中附带的 Python 注释将输入和输出绑定到方法。
Azure Functions 要求函数是 Python 脚本中处理输入并生成输出的无状态方法。 默认情况下,运行时期望方法在 function_app.py 文件中作为全局方法实现。
可以使用基于修饰器的方法声明触发器和绑定,并函数中使用它们。 它们在与函数相同的文件 function_app.py 中定义。 例如,以下 function_app.py 文件表示 HTTP 请求的函数触发器。
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req):
user = req.params.get("user")
return f"Hello, {user}!"
还可以使用 Python 类型注释在函数中显式声明属性类型和返回类型。 此操作有助于使用许多 Python 代码编辑器提供的 IntelliSense 和自动完成功能。
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> str:
user = req.params.get("user")
return f"Hello, {user}!"
若要了解 v2 模型的已知限制及其解决方法,请参阅排查 Azure Functions 中的 Python 错误。
替代入口点
可以选择在 function.json 文件中指定 scriptFile 和 entryPoint 属性来更改函数的默认行为。 例如,下面的 function.json 指示运行时使用 main.py 文件中的 customentry() 方法作为 Azure 函数的入口点。
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
入口点只能在 function_app.py 文件中。 但是,可以使用蓝图或通过导入在 function_app.py 中引用项目中的函数。
文件夹结构
Python 函数项目的建议文件夹结构如以下示例所示:
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
主项目文件夹 <project_root> 可以包含以下文件:
- local.settings.json:用于在本地运行时存储应用设置和连接字符串。 此文件不会被发布到 Azure。 若要了解详细信息,请参阅 local.settings.file。
- requirements.txt:包含在发布到 Azure 时系统安装的 Python 包列表。
- host.json:包含在函数应用实例中影响所有函数的配置选项。 此文件会被发布到 Azure。 本地运行时,并非所有选项都受支持。 若要了解详细信息,请参阅 host.json。
- .vscode/:(可选)包含存储的 Visual Studio Code 配置。 若要了解详细信息,请参阅 Visual Studio Code 设置。
- .venv/:(可选)包含本地开发使用的 Python 虚拟环境。
- Dockerfile:(可选)在自定义容器中发布项目时使用。
- tests/:(可选)包含函数应用的测试用例。
- .funcignore:(可选)声明不应发布到 Azure 的文件。 通常,此文件包含 .vscode/ 以忽略编辑器设置,包含 .venv/ 以忽略本地 Python 虚拟环境,包含 tests/ 以忽略测试用例,包含 local.settings.json 以阻止发布本地应用设置。
每个函数都有自己的代码文件和绑定配置文件 function.json。
Python 函数项目的建议文件夹结构如以下示例所示:
<project_root>/
| - .venv/
| - .vscode/
| - function_app.py
| - additional_functions.py
| - tests/
| | - test_my_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
主项目文件夹 <project_root> 可以包含以下文件:
- .venv/:(可选)包含本地开发使用的 Python 虚拟环境。
- .vscode/:(可选)包含存储的 Visual Studio Code 配置。 若要了解详细信息,请参阅 Visual Studio Code 设置。
- function_app.py:所有函数及其相关触发器和绑定的默认位置。
- additional_functions.py:(可选)包含通过蓝图在 function_app.py 中引用的函数(通常用于逻辑分组)的任何其他 Python 文件。
- tests/:(可选)包含函数应用的测试用例。
- .funcignore:(可选)声明不应发布到 Azure 的文件。 通常,此文件包含 .vscode/ 以忽略编辑器设置,包含 .venv/ 以忽略本地 Python 虚拟环境,包含 tests/ 以忽略测试用例,包含 local.settings.json 以阻止发布本地应用设置。
- host.json:包含在函数应用实例中影响所有函数的配置选项。 此文件会被发布到 Azure。 本地运行时,并非所有选项都受支持。 若要了解详细信息,请参阅 host.json。
- local.settings.json:用于在本地运行时存储应用设置和连接字符串。 此文件不会被发布到 Azure。 若要了解详细信息,请参阅 local.settings.file。
- requirements.txt:包含在发布到 Azure 时系统安装的 Python 包列表。
- Dockerfile:(可选)在自定义容器中发布项目时使用。
在 Azure 中将项目部署到函数应用时,主项目文件夹<project_root> 的整个内容应包含在包中,但不包含该文件夹本身,这意味着 host.json 应位于包根目录中。 建议你在一个文件夹中维护测试以及其他函数,在此示例中为 tests/。 有关详细信息,请参阅单元测试。
连接到数据库
Azure Functions 与 Azure Cosmos DB 良好集成,适用于许多用例,包括 IoT、电子商务、游戏等。
例如,对于事件源,这两项服务集成在一起,利用 Azure Cosmos DB 的更改源功能来支持事件驱动的体系结构。 更改源使下游微服务能够可靠地以增量方式读取插入和更新(例如订单事件)。 使用此功能可以提供一个持久性的事件存储作为状态不断变化的事件的消息中转站,并驱动许多微服务之间的订单处理工作流(可实现为无服务器 Azure Functions)。
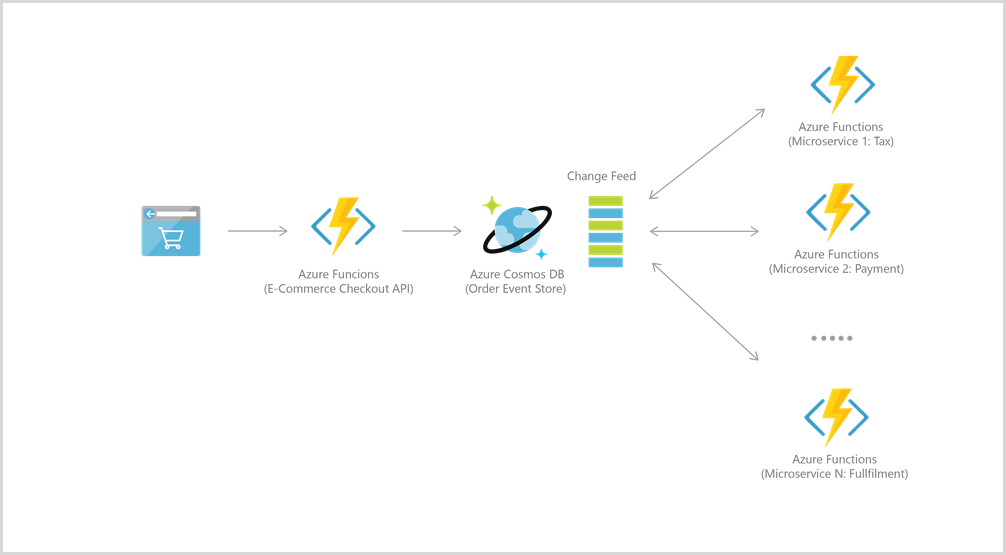
若要连接到 Azure Cosmos DB,请首先创建帐户、数据库和容器。 然后就可以使用触发器和绑定将函数代码连接到 Azure Cosmos DB,就像此示例一样。
要实现更复杂的应用逻辑,还可以使用 Cosmos DB 的 Python 库。 异步 I/O 实现如下所示:
pip install azure-cosmos
pip install aiohttp
from azure.cosmos.aio import CosmosClient
from azure.cosmos import exceptions
from azure.cosmos.partition_key import PartitionKey
import asyncio
# Replace these values with your Cosmos DB connection information
endpoint = "https://azure-cosmos-nosql.documents.azure.cn:443/"
key = "master_key"
database_id = "cosmicwerx"
container_id = "cosmicontainer"
partition_key = "/partition_key"
# Set the total throughput (RU/s) for the database and container
database_throughput = 1000
# Singleton CosmosClient instance
client = CosmosClient(endpoint, credential=key)
# Helper function to get or create database and container
async def get_or_create_container(client, database_id, container_id, partition_key):
database = await client.create_database_if_not_exists(id=database_id)
print(f'Database "{database_id}" created or retrieved successfully.')
container = await database.create_container_if_not_exists(id=container_id, partition_key=PartitionKey(path=partition_key))
print(f'Container with id "{container_id}" created')
return container
async def create_products():
container = await get_or_create_container(client, database_id, container_id, partition_key)
for i in range(10):
await container.upsert_item({
'id': f'item{i}',
'productName': 'Widget',
'productModel': f'Model {i}'
})
async def get_products():
items = []
container = await get_or_create_container(client, database_id, container_id, partition_key)
async for item in container.read_all_items():
items.append(item)
return items
async def query_products(product_name):
container = await get_or_create_container(client, database_id, container_id, partition_key)
query = f"SELECT * FROM c WHERE c.productName = '{product_name}'"
items = []
async for item in container.query_items(query=query, enable_cross_partition_query=True):
items.append(item)
return items
async def main():
await create_products()
all_products = await get_products()
print('All Products:', all_products)
queried_products = await query_products('Widget')
print('Queried Products:', queried_products)
if __name__ == "__main__":
asyncio.run(main())
蓝图
Python v2 编程模型引入了蓝图的概念。 蓝图是一个实例化的新类,用于在核心函数应用程序之外注册函数。 蓝图实例中注册的函数不直接由函数运行时编制索引。 若要为这些蓝图函数编制索引,函数应用需要从蓝图实例注册这些函数。
使用蓝图可获得以下好处:
- 可以将函数应用分解为模块化组件,从而可以在多个 Python 文件中定义函数,并将其划分为每个文件的不同组件。
- 提供可扩展的公共函数应用接口用于生成和重用你自己的 API。
以下示例演示了如何使用蓝图:
首先,在 http_blueprint.py 文件中定义 HTTP 触发的函数并将其添加到蓝图对象。
import logging
import azure.functions as func
bp = func.Blueprint()
@bp.route(route="default_template")
def default_template(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(
f"Hello, {name}. This HTTP-triggered function "
f"executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. "
"Pass a name in the query string or in the request body for a"
" personalized response.",
status_code=200
)
接下来,在 function_app.py 文件中,导入蓝图对象并将其函数注册到函数应用。
import azure.functions as func
from http_blueprint import bp
app = func.FunctionApp()
app.register_functions(bp)
注意
Durable Functions 还支持蓝图。 要为 Durable Functions 应用创建蓝图,请使用 azure-functions-durable Blueprint 类注册业务流程、活动、实体触发器和客户端绑定,如此处所示。 然后,生成的蓝图便可以正常注册。 有关示例,请参阅我们的示例。
导入行为
可以使用绝对引用和相对引用在函数代码中导入模块。 根据上面所述的文件夹结构,以下导入在函数文件 <project_root>\my_first_function\__init__.py 中工作:
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
注意
使用绝对导入语法时,shared_code/ 文件夹需要包含 __init__.py 文件以将其标记为 Python 包。
以下 __app__ 导入和 beyond top-level 相对导入已弃用,因为它们不受静态类型检查器支持,且不受 Python 测试框架支持:
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
触发器和输入
在 Azure Functions 中,输入分为两种类别:触发器输入和其他输入。 虽然它们在 function.json 文件中并不相同,但它们在 Python 代码中的使用方法却是相同的。 在本地运行时,触发器和输入源的连接字符串或机密映射到 local.settings.json 文件中的值;在 Azure 中运行时,它们映射到应用程序设置。
例如,以下代码演示了两个输入之间的差异:
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "STORAGE_CONNECTION_STRING"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
调用函数时,HTTP 请求作为 req 传递给函数。 将基于路由 URL 中的 ID 从 Azure Blob 存储帐户检索一个条目,并在函数体中用作 obj。 在这里,指定的存储帐户是在 CONNECTION_STRING 应用设置中找到的连接字符串。
在 Azure Functions 中,输入分为两种类别:触发器输入和其他输入。 尽管它们是使用不同的修饰器定义的,但在 Python 代码中的用法相似。 在本地运行时,触发器和输入源的连接字符串或机密映射到 local.settings.json 文件中的值;在 Azure 中运行时,它们映射到应用程序设置。
例如,以下代码演示了如何定义 Blob 存储输入绑定:
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# function_app.py
import azure.functions as func
import logging
app = func.FunctionApp()
@app.route(route="req")
@app.read_blob(arg_name="obj", path="samples/{id}",
connection="STORAGE_CONNECTION_STRING")
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
调用函数时,HTTP 请求作为 req 传递给函数。 将基于路由 URL 中的 ID 从 Azure Blob 存储帐户检索一个条目,并在函数体中用作 obj。 在这里,指定的存储帐户是在 STORAGE_CONNECTION_STRING 应用设置中找到的连接字符串。
对于数据密集型绑定操作,你可能希望使用单独的存储帐户。 有关详细信息,请参阅存储帐户指导。
SDK 类型绑定(预览版)
为了选择触发器和绑定,可以使用基础 Azure SDK 和框架实现的数据类型。 这些 SDK 类型绑定让你像使用基础服务 SDK 一样交互绑定数据。
重要
对 SDK 类型绑定的支持需要 Python v2 编程模型。
Functions 支持用于 Azure Blob 存储的 Python SDK 类型绑定,这使你可以使用基础 BlobClient 类型处理 blob 数据。
重要
对 Python 的 SDK 类型绑定支持目前为预览版:
- 必须使用 Python v2 编程模型。
- 目前,仅支持同步 SDK 类型。
先决条件
- Azure Functions 运行时版本 4.34 或更高版本。
- Python 版本 3.9 或支持的更高版本。
为 Blob 存储扩展启用 SDK 类型绑定
- 将
azurefunctions-extensions-bindings-blob扩展包添加到项目的requirements.txt文件中,其中至少应包括以下包:
azure-functions
azurefunctions-extensions-bindings-blob
- 将以下代码添加到项目的
function_app.py文件中,将导入 SDK 类型绑定:
import azurefunctions.extensions.bindings.blob as blob
SDK 类型绑定示例
以下示例演示如何从 Blob 存储触发器 (blob_trigger) 和 HTTP 触发器 (blob_input) 上的输入绑定获取 BlobClient:
import logging
import azure.functions as func
import azurefunctions.extensions.bindings.blob as blob
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.blob_trigger(
arg_name="client", path="PATH/TO/BLOB", connection="AzureWebJobsStorage"
)
def blob_trigger(client: blob.BlobClient):
logging.info(
f"Python blob trigger function processed blob \n"
f"Properties: {client.get_blob_properties()}\n"
f"Blob content head: {client.download_blob().read(size=1)}"
)
@app.route(route="file")
@app.blob_input(
arg_name="client", path="PATH/TO/BLOB", connection="AzureWebJobsStorage"
)
def blob_input(req: func.HttpRequest, client: blob.BlobClient):
logging.info(
f"Python blob input function processed blob \n"
f"Properties: {client.get_blob_properties()}\n"
f"Blob content head: {client.download_blob().read(size=1)}"
)
return "ok"
可以在 Python 扩展存储库中查看 Blob 存储的其他 SDK 类型绑定示例:
HTTP 流(预览版)
HTTP 流允许你使用函数中启用的 FastAPI 请求和响应 API 接受和返回来自 HTTP 终结点的数据。 这些 API 允许主机将 HTTP 消息中的大型数据作为区块处理,而不是将整个消息读取到内存中。
利用此功能,可以处理大型数据流集成、提供动态内容并支持需要通过 HTTP 进行实时交互的其他核心 HTTP 方案。 还可以将 FastAPI 响应类型与 HTTP 流配合使用。 如果没有 HTTP 流,HTTP 请求和响应的大小受内存限制,在处理内存中所有消息有效负载时可能会遇到这些限制。
重要
对 HTTP 流的支持需要 Python v2 编程模型。
重要
对 Python 的 HTTP 流支持目前为预览版,需要使用 Python v2 编程模型。
先决条件
- Azure Functions 运行时版本 4.34.1 或更高版本。
- Python 版本 3.8 或支持的更高版本。
启用 HTTP 流
默认已禁用 HTTP 流。 需要在应用程序设置中启用此功能,并更新代码以使用 FastAPI 包。 请注意,启用 HTTP 流时,函数应用将默认使用 HTTP 流式处理,原始 HTTP 功能将不起作用。
- 将
azurefunctions-extensions-http-fastapi扩展包添加到项目的requirements.txt文件中,其中至少应包括以下包:
azure-functions
azurefunctions-extensions-http-fastapi
- 将以下代码添加到项目的
function_app.py文件中,将导入 FastAPI 扩展:
from azurefunctions.extensions.http.fastapi import Request, StreamingResponse
部署到 Azure 时,请在函数应用中添加以下应用程序设置:
"PYTHON_ENABLE_INIT_INDEXING": "1"如果要部署到 Linux 消耗计划,请同时添加
"PYTHON_ISOLATE_WORKER_DEPENDENCIES": "1"在本地运行时,还需要将同样的设置添加到
local.settings.json项目文件。
HTTP 流示例
启用 HTTP 流式处理功能后,可以创建通过 HTTP 流式传输数据的函数。
以下示例是一个 HTTP 触发的函数,用于流式传输 HTTP 响应数据。 可以使用这些功能来支持诸如通过管道发送事件数据以实时可视化或检测大量数据中的异常并提供即时通知等场景。
import time
import azure.functions as func
from azurefunctions.extensions.http.fastapi import Request, StreamingResponse
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
def generate_sensor_data():
"""Generate real-time sensor data."""
for i in range(10):
# Simulate temperature and humidity readings
temperature = 20 + i
humidity = 50 + i
yield f"data: {{'temperature': {temperature}, 'humidity': {humidity}}}\n\n"
time.sleep(1)
@app.route(route="stream", methods=[func.HttpMethod.GET])
async def stream_sensor_data(req: Request) -> StreamingResponse:
"""Endpoint to stream real-time sensor data."""
return StreamingResponse(generate_sensor_data(), media_type="text/event-stream")
以下示例是一个 HTTP 触发的函数,用于实时接收和处理来自客户端的流数据。 它演示了流式上传功能,此功能对于处理连续数据流和处理 IoT 设备中的事件数据等场景非常有用。
import azure.functions as func
from azurefunctions.extensions.http.fastapi import JSONResponse, Request
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.route(route="streaming_upload", methods=[func.HttpMethod.POST])
async def streaming_upload(req: Request) -> JSONResponse:
"""Handle streaming upload requests."""
# Process each chunk of data as it arrives
async for chunk in req.stream():
process_data_chunk(chunk)
# Once all data is received, return a JSON response indicating successful processing
return JSONResponse({"status": "Data uploaded and processed successfully"})
def process_data_chunk(chunk: bytes):
"""Process each data chunk."""
# Add custom processing logic here
pass
调用 HTTP 流
必须使用 HTTP 客户端库对函数的 FastAPI 终结点进行流式处理调用。 你使用的客户端工具或浏览器可能无法本机支持流式处理,或者只能返回第一个数据块。
可以使用如下所示的客户端脚本将流式处理数据发送到 HTTP 终结点:
import httpx # Be sure to add 'httpx' to 'requirements.txt'
import asyncio
async def stream_generator(file_path):
chunk_size = 2 * 1024 # Define your own chunk size
with open(file_path, 'rb') as file:
while chunk := file.read(chunk_size):
yield chunk
print(f"Sent chunk: {len(chunk)} bytes")
async def stream_to_server(url, file_path):
timeout = httpx.Timeout(60.0, connect=60.0)
async with httpx.AsyncClient(timeout=timeout) as client:
response = await client.post(url, content=stream_generator(file_path))
return response
async def stream_response(response):
if response.status_code == 200:
async for chunk in response.aiter_raw():
print(f"Received chunk: {len(chunk)} bytes")
else:
print(f"Error: {response}")
async def main():
print('helloworld')
# Customize your streaming endpoint served from core tool in variable 'url' if different.
url = 'http://localhost:7071/api/streaming_upload'
file_path = r'<file path>'
response = await stream_to_server(url, file_path)
print(response)
if __name__ == "__main__":
asyncio.run(main())
Outputs
输出可以在返回值和输出参数中进行表示。 如果只有一个输出,则建议使用返回值。 对于多个输出,必须使用输出参数。
若要使用函数的返回值作为输出绑定的值,则绑定的 name 属性应在 function.json 文件中设置为 $return。
若要生成多个输出,请使用 azure.functions.Out 接口提供的 set() 方法将值分配给绑定。 例如,以下函数可以将消息推送到队列,还可返回 HTTP 响应。
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "STORAGE_CONNECTION_STRING"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
输出可以在返回值和输出参数中进行表示。 如果只有一个输出,则建议使用返回值。 对于多个输出,必须使用输出参数。
若要生成多个输出,请使用 azure.functions.Out 接口提供的 set() 方法将值分配给绑定。 例如,以下函数可以将消息推送到队列,还可返回 HTTP 响应。
# function_app.py
import azure.functions as func
app = func.FunctionApp()
@app.write_blob(arg_name="msg", path="output-container/{name}",
connection="CONNECTION_STRING")
def test_function(req: func.HttpRequest,
msg: func.Out[str]) -> str:
message = req.params.get('body')
msg.set(message)
return message
日志记录
可在函数应用中通过根 logging 处理程序来访问 Azure Functions 运行时记录器。 此记录器绑定到 Application Insights,并允许标记在函数执行期间遇到的警告和错误。
下面的示例在通过 HTTP 触发器调用函数时记录信息消息。
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
有更多日志记录方法可用于在不同跟踪级别向控制台进行写入:
| 方法 | 说明 |
|---|---|
critical(_message_) |
在根记录器中写入具有 CRITICAL 级别的消息。 |
error(_message_) |
在根记录器中写入具有 ERROR 级别的消息。 |
warning(_message_) |
在根记录器中写入具有 WARNING 级别的消息。 |
info(_message_) |
在根记录器中写入具有 INFO 级别的消息。 |
debug(_message_) |
在根记录器中写入具有 DEBUG 级别的消息。 |
若要详细了解日志记录,请参阅监视 Azure Functions。
来自所创建线程的日志记录
要查看来自所创建线程的日志,请在函数的签名中包含 context 参数。 此参数包含属性 thread_local_storage,该属性可存储本地 invocation_id。 可将其设置为函数的当前 invocation_id,以确保更改上下文。
import azure.functions as func
import logging
import threading
def main(req, context):
logging.info('Python HTTP trigger function processed a request.')
t = threading.Thread(target=log_function, args=(context,))
t.start()
def log_function(context):
context.thread_local_storage.invocation_id = context.invocation_id
logging.info('Logging from thread.')
记录自定义遥测数据
默认情况下,函数运行时会收集函数生成的日志和其他遥测数据。 此遥测最终会作为 Application Insights 中的跟踪。 默认情况下,某些 Azure 服务的请求和依赖项遥测还通过触发器和绑定进行收集。
若要收集自定义请求和自定义依赖项遥测(在绑定之外),可以使用 OpenCensus Python 扩展。 此扩展将自定义遥测数据发送到应用程序 Insights 实例。 可以在 OpenCensus 存储库中找到受支持的扩展的列表。
注意
若要使用 OpenCensus Python 扩展,需要通过将 PYTHON_ENABLE_WORKER_EXTENSIONS 设置为 1,在函数应用中启用 Python 辅助角色扩展。 还需要切换为使用 Application Insights 连接字符串,方法是将 APPLICATIONINSIGHTS_CONNECTION_STRING 设置添加到应用程序设置(如果不存在)。
// requirements.txt
...
opencensus-extension-azure-functions
opencensus-ext-requests
import json
import logging
import requests
from opencensus.extension.azure.functions import OpenCensusExtension
from opencensus.trace import config_integration
config_integration.trace_integrations(['requests'])
OpenCensusExtension.configure()
def main(req, context):
logging.info('Executing HttpTrigger with OpenCensus extension')
# You must use context.tracer to create spans
with context.tracer.span("parent"):
response = requests.get(url='http://example.com')
return json.dumps({
'method': req.method,
'response': response.status_code,
'ctx_func_name': context.function_name,
'ctx_func_dir': context.function_directory,
'ctx_invocation_id': context.invocation_id,
'ctx_trace_context_Traceparent': context.trace_context.Traceparent,
'ctx_trace_context_Tracestate': context.trace_context.Tracestate,
'ctx_retry_context_RetryCount': context.retry_context.retry_count,
'ctx_retry_context_MaxRetryCount': context.retry_context.max_retry_count,
})
HTTP 触发器
HTTP 触发器在 function.json 文件中定义。 绑定的 name 必须与函数中的命名参数匹配。
前面的示例中使用了绑定名称 req。 此参数是 HttpRequest 对象,并返回 HttpResponse 对象。
从 HttpRequest 对象中,可以获取请求标头、查询参数、路由参数和消息正文。
以下示例来自适用于 Python 的 HTTP 触发器模版。
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
在此函数中,从 HttpRequest 对象的 params 参数获取 name 查询参数的值。 使用 get_json 方法读取 JSON 编码的消息正文。
同样,你可以在返回的 HttpResponse 对象中为响应消息设置 status_code 和 headers。
HTTP 触发器定义为一种方法,该方法采用命名绑定参数(即 HttpRequest 对象)并返回 HttpResponse 对象。 请将 function_name 装饰器应用于方法来定义函数名称,同时通过应用 route 装饰器来设置 HTTP 终结点。
以下示例取自 Python v2 编程模型的 HTTP 触发器模板,其中的绑定参数名称为 req。 它是使用 Azure Functions Core Tools 或 Visual Studio Code 创建函数时提供的示例代码。
@app.function_name(name="HttpTrigger1")
@app.route(route="hello")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello, {name}. This HTTP-triggered function executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)
从 HttpRequest 对象中,可以获取请求标头、查询参数、路由参数和消息正文。 在此函数中,从 HttpRequest 对象的 params 参数获取 name 查询参数的值。 使用 get_json 方法读取 JSON 编码的消息正文。
同样,你可以在返回的 HttpResponse 对象中为响应消息设置 status_code 和 headers。
若要在此示例中传入名称,请粘贴运行函数时提供的 URL,并在其后面追加 "?name={name}"。
Web 框架
可以将 Web 服务器网关接口 (WSGI) 兼容的框架和异步服务器网关接口 (ASGI) 兼容的框架(例如 Flask 和 FastAPI)用于 HTTP 触发的 Python 函数。 本部分介绍如何修改函数以支持这些框架。
首先,必须更新 function.json 文件,使其在 HTTP 触发器中包含 route,如以下示例中所示:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "{*route}"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
还必须更新 host.json 文件,使其包含 HTTP routePrefix,如以下示例中所示:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[3.*, 4.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
根据框架使用的接口,更新 Python 代码文件 init.py。 下面的示例展示了 ASGI 处理程序方法或 Flask 的 WSGI 包装器方法:
可以将异步服务器网关接口 (ASGI) 兼容的框架和 Web 服务器网关接口 (WSGI) 兼容的框架(例如 Flask 和 FastAPI)用于 HTTP 触发的 Python 函数。 必须先更新 host.json 文件以包含 HTTP routePrefix,如以下示例所示:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[2.*, 3.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
框架代码如以下示例所示:
AsgiFunctionApp 是用于构造 ASGI HTTP 函数的顶级函数应用类。
# function_app.py
import azure.functions as func
from fastapi import FastAPI, Request, Response
fast_app = FastAPI()
@fast_app.get("/return_http_no_body")
async def return_http_no_body():
return Response(content="", media_type="text/plain")
app = func.AsgiFunctionApp(app=fast_app,
http_auth_level=func.AuthLevel.ANONYMOUS)
缩放和性能
有关 Python 函数应用的缩放和性能最佳做法,请参阅 Python 缩放和性能一文。
上下文
若要在运行某个函数时获取其调用上下文,请在其签名中包含 context 参数。
例如:
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
Context 类具有以下字符串属性:
| 属性 | 说明 |
|---|---|
function_directory |
在其中运行函数的目录。 |
function_name |
函数的名称。 |
invocation_id |
当前函数调用的 ID。 |
thread_local_storage |
函数的线程本地存储。 包含可用于invocation_id来自所创建线程的日志记录的本地 。 |
trace_context |
分布式跟踪的上下文。 有关详细信息,请参阅 Trace Context。 |
retry_context |
函数的重试上下文。 有关详细信息,请参阅 retry-policies。 |
全局变量
应用的状态是否将保留,以供将来执行使用,这一点不能保证。 但是,Azure Functions 运行时通常会为同一应用的多次执行重复使用同一进程。 若要缓存高开销计算的结果,请将其声明为全局变量。
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
环境变量
在 Azure Functions 中,服务连接字符串等应用程序设置在运行时将公开为环境变量。 在代码中访问这些设置有两种主要方法。
| 方法 | 说明 |
|---|---|
os.environ["myAppSetting"] |
尝试按键名称获取应用程序设置,失败时会引发错误。 |
os.getenv("myAppSetting") |
尝试按键名称获取应用程序设置,失败时会返回 None。 |
这两种方法都需要声明 import os。
以下示例使用名为 myAppSetting 的键通过 os.environ["myAppSetting"] 获取应用程序设置:
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
对于本地开发,应用程序设置在 local.settings.json 文件中维护。
在 Azure Functions 中,服务连接字符串等应用程序设置在运行时将公开为环境变量。 在代码中访问这些设置有两种主要方法。
| 方法 | 说明 |
|---|---|
os.environ["myAppSetting"] |
尝试按键名称获取应用程序设置,失败时会引发错误。 |
os.getenv("myAppSetting") |
尝试按键名称获取应用程序设置,失败时会返回 None。 |
这两种方法都需要声明 import os。
以下示例使用名为 myAppSetting 的键通过 os.environ["myAppSetting"] 获取应用程序设置:
import logging
import os
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
对于本地开发,应用程序设置在 local.settings.json 文件中维护。
Python 版本
Azure Functions 支持以下 Python 版本:
| Functions 版本 | Python* 版本 |
|---|---|
| 4.x | 3.11 3.10 3.9 3.8 3.7 |
| 3.x | 3.9 3.8 3.7 |
* 官方 Python 发行版
若要在 Azure 中创建函数应用时请求特定的 Python 版本,请使用 az functionapp create 命令的 --runtime-version 选项。 函数运行时版本由 --functions-version 选项设置。 Python 版本是在创建函数应用时设置的,不能为在消耗计划中运行的应用更改它。
运行时在本地运行时使用可用的 Python 版本。
更改 Python 版本
若要将 Python 函数应用设置为特定的语言版本,需要在站点配置中的 LinuxFxVersion 字段内指定语言以及语言版本。 例如,若要将 Python 应用更改为使用 Python 3.8,请将 linuxFxVersion 设置为 python|3.8。
若要了解如何查看和更改 linuxFxVersion 站点设置,请参阅如何面向 Azure Functions 运行时版本。
有关更多一般信息,请参阅 Azure Functions 运行时支持策略和 Azure Functions 中支持的语言。
包管理
在使用 Core Tools 或 Visual Studio Code 进行本地开发时,将所需包的名称和版本添加到 requirements.txt 文件,然后使用 pip 安装它们。
例如,可以使用以下 requirements.txt 文件和 pip 命令从 PyPI 安装 requests 包。
requests==2.19.1
pip install -r requirements.txt
在应用服务计划中运行函数时,在 requirements.txt 中定义的依赖项优先于内置 Python 模块,例如 logging。 当内置模块与代码中的目录具有相同名称时,此优先顺序可能会导致冲突。 在消耗计划或弹性高级计划中运行时,发生冲突的可能性较小,因为默认情况下依赖项没有优先级。
为了防止在应用服务计划中运行时出现问题,请不要将目录命名为与任何 Python 原生模块相同的名称,并且不要在项目的 requirements.txt 文件中包含 Python 原生库。
发布到 Azure
准备好进行发布时,确保所有公开发布的依赖项都在 requirements.txt 文件中列出。 可以在项目目录的根目录中找到此文件。
可以在项目的根目录中找到从发布中排除的项目文件和文件夹,包括虚拟环境文件夹。
将 Python 项目发布到 Azure 时,支持三种生成操作:远程生成、本地生成以及使用自定义依赖项生成。
还可使用 Azure Pipelines 生成依赖项并使用持续交付 (CD) 发布。
远程生成
使用远程生成时,服务器上还原的依赖项和本机依赖项与生产环境匹配。 这导致要上传的部署包较小。 在 Windows 上开发 Python 应用时使用远程生成。 如果你的项目具有自定义依赖项,可使用具有额外索引 URL 的远程生成。
依赖项根据 requirements.txt 文件的内容远程获取。 远程生成是推荐的生成方法。 默认情况下,使用下面的 func azure functionapp publish 命令将 Python 项目发布到 Azure 时,Core Tools 会请求远程生成。
func azure functionapp publish <APP_NAME>
请记住将 <APP_NAME> 替换为 Azure 中的函数应用名称。
默认情况下,适用于 Visual Studio Code 的 Azure Functions 扩展还会请求远程生成。
本地生成
依赖项根据 requirements.txt 文件的内容在本地获取。 可以使用下面的 func azure functionapp publish 命令通过本地生成来发布,从而防止执行远程生成:
func azure functionapp publish <APP_NAME> --build local
请记住将 <APP_NAME> 替换为 Azure 中的函数应用名称。
使用 --build local 选项时,将从 requirements.txt 文件中读取项目依赖项,并在本地下载和安装这些依赖包。 项目文件和依赖项从本地计算机部署到 Azure。 这会将较大的部署包上传到 Azure。 如果由于某种原因无法使用 Core Tools 获取 requirements.txt 文件中的依赖项,则必须使用自定义依赖项选项进行发布。
在 Windows 上进行本地开发时,不建议使用本地生成。
自定义依赖项
如果项目的依赖项在 Python 包索引中找不到,可通过两种方式生成该项目。 第一种生成方法取决于你生成项目的方式。
具有额外索引 URL 的远程生成
如果包可以从可访问的自定义包索引中获取,请使用远程生成。 在发布之前,请务必创建一个名为 PIP_EXTRA_INDEX_URL 的应用设置。 此设置的值是自定义包索引的 URL。 使用此设置可告诉远程生成使用 --extra-index-url 选项运行 pip install。 若要了解详细信息,请参阅 Python pip install 文档。
还可将基本身份验证凭据与额外的包索引 URL 结合使用。 若要了解详细信息,请参阅 Python 文档中的基本身份验证凭据。
安装本地包
如果你的项目使用未向我们的工具公开发布的包,则可以通过将包放在 __app__/.python_packages 目录中,使其可供应用使用。 发布之前,运行以下命令以在本地安装依赖项:
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
使用自定义依赖项时,应使用 --no-build 发布选项,因为你已将依赖项安装到项目文件夹中。
func azure functionapp publish <APP_NAME> --no-build
请记住将 <APP_NAME> 替换为 Azure 中的函数应用名称。
单元测试
可以使用标准测试框架,像测试其他 Python 代码一样测试以 Python 编写的函数。 对于大多数绑定,可以通过从 azure.functions 包创建适当类的实例来创建 mock 输入对象。 由于 azure.functions 包不可供立即可用,请务必通过 requirements.txt 文件安装该包,如上文包管理部分所述。
以 my_second_function 为例,下面是 HTTP 触发的函数的模拟测试:
首先创建 <project_root>/my_second_function/function.json 文件并将此函数定义为 HTTP 触发器。
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
接下来,可以实现 my_second_function 和 shared_code.my_second_helper_function。
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
可以开始为 HTTP 触发器编写测试用例。
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(resp.get_body(), b'21 * 2 = 42',)
在 .venv Python 虚拟环境文件夹中安装你偏好的 Python 测试框架,例如 pip install pytest。 然后运行 pytest tests 即可检查测试结果。
首先创建 <project_root>/function_app.py 文件,并将 my_second_function 函数实现为 HTTP 触发器和 shared_code.my_second_helper_function。
# <project_root>/function_app.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
app = func.FunctionApp()
# Define the HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
@app.function_name(name="my_second_function")
@app.route(route="hello")
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
可以开始为 HTTP 触发器编写测试用例。
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from function_app import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
func_call = main.build().get_user_function()
resp = func_call(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
在 .venv Python 虚拟环境文件夹中安装你偏好的 Python 测试框架,例如 pip install pytest。 然后运行 pytest tests 即可检查测试结果。
临时文件
tempfile.gettempdir() 方法返回一个临时文件夹,在 Linux 上为 /tmp。 应用程序可使用此目录存储函数在运行时生成和使用的临时文件。
重要
不能保证写入临时目录的文件会在调用之间保留。 在横向扩展期间,临时文件不会在实例之间进行共享。
以下示例在临时目录 (/tmp) 中创建一个命名的临时文件:
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
建议在独立于项目文件夹的文件夹中维护测试。 此操作可防止对应用部署测试代码。
预安装的库
Python 函数运行时附带了一些库。
Python 标准库
Python 标准库包含每个 Python 发行版附带的内置 Python 模块列表。 其中的大多数库可帮助你访问系统功能,例如文件输入/输出 (I/O)。 在 Windows 系统上,这些库随 Python 一起安装。 在基于 Unix 的系统上,它们由包集合提供。
若要查看适用于你的 Python 版本的库,请转到:
Azure Functions Python 辅助角色依赖项
Azure Functions Python 工作进程需要一组特定的库。 你也可以在函数中使用这些库,但它们并不属于 Python 标准库。 如果你的函数依赖于这些库中的任何一个库,则在 Azure Functions 之外运行时,这些函数可能无法用于代码。
注意
如果函数应用的 requirements.txt 文件包含 azure-functions-worker 条目,请将其删除。 函数工作进程由 Azure Functions 平台自动管理,我们会定期更新新功能和 Bug 修补程序。 在 requirements.txt 文件中手动安装旧版本的工作进程可能会导致意外问题。
注意
如果你的包包含可能与工作进程的依赖项冲突的某些库(例如 protobuf、tensorflow 或 grpcio),请在应用设置中将 PYTHON_ISOLATE_WORKER_DEPENDENCIES 配置为 1,以防止应用程序引用该工作进程的依赖项。
Azure Functions Python 库
每次 Python 工作进程更新都包含一个新版本的 Azure Functions Python 库 (azure.functions)。 这种方法使持续更新 Python 函数应用变得更容易,因为每次更新都是向后兼容的。 有关此库的版本列表,请参阅 azure-functions PyPi。
运行时库版本由 Azure 修复,不能通过 requirements.txt 替代。 requirements.txt 中的 azure-functions 条目仅供 Lint 分析和客户认知。
使用以下代码在运行时中跟踪 Python 函数库的实际版本:
getattr(azure.functions, '__version__', '< 1.2.1')
运行时系统库
有关 Python 工作进程 Docker 映像中预装的系统库列表,请参阅以下主题:
| Functions 运行时 | Debian 版本 | Python 版本 |
|---|---|---|
| 3\.x 版 | Buster | Python 3.7 Python 3.8 Python 3.9 |
Python 辅助角色扩展
在 Azure Functions 中运行的 Python 工作进程允许将第三方库集成到函数应用中。 这些扩展库充当中间件,可以在执行函数的生命周期内注入特定操作。
在与标准 Python 库模块类似的函数代码中导入扩展。 扩展基于以下范围运行:
| 范围 | 说明 |
|---|---|
| 应用程序级 | 导入到任何函数触发器中时,扩展适用于应用中的每个函数执行。 |
| 函数级 | 执行仅限于导入到其中的特定函数触发器。 |
查看每个扩展的信息,以详细了解扩展的运行范围。
扩展实现 Python 辅助角色扩展接口。 此操作允许 Python 工作进程在函数执行生命周期内调入扩展代码。 若要了解详细信息,请参阅创建扩展。
使用扩展
可以通过执行以下操作在 Python 函数中使用 Python 工作进程扩展库:
- 在项目的 requirements.txt 文件中添加扩展包。
- 将库安装到应用中。
- 添加以下应用程序设置:
- 本地:在 local.settings.json 文件的
Values部分输入"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"。 - Azure:在应用设置中输入
PYTHON_ENABLE_WORKER_EXTENSIONS=1。
- 本地:在 local.settings.json 文件的
- 将扩展模块导入到函数触发器中。
- 配置扩展实例(如果需要)。 应在扩展文档中标注配置要求。
重要
Microsoft 不支持或保证第三方 Python 工作进程扩展库。 必须确保在函数应用中使用的任何扩展都是可信的,并且你承担使用恶意扩展或编写不当的扩展的全部风险。
第三方应会提供有关如何在函数应用中安装和使用其扩展的具体文档。 有关如何使用扩展的基本示例,请参阅使用扩展。
下面是在函数应用中按范围使用扩展的示例:
# <project_root>/requirements.txt
application-level-extension==1.0.0
# <project_root>/Trigger/__init__.py
from application_level_extension import AppExtension
AppExtension.configure(key=value)
def main(req, context):
# Use context.app_ext_attributes here
创建扩展
扩展是由已创建可集成到 Azure Functions 中的功能的第三方库开发人员创建的。 扩展开发人员设计、实现和发布 Python 包,其中包含专为在函数执行上下文中运行而设计的自定义逻辑。 这些扩展可以发布到 PyPI 注册表或 GitHub 存储库。
若要了解如何创建、打包、发布和使用 Python 辅助角色扩展包,请参阅为 Azure Functions 开发 Python 辅助角色扩展。
应用程序级扩展
继承自 AppExtensionBase 的扩展在应用程序范围内运行。
AppExtensionBase 公开以下抽象类方法以供你实现:
| 方法 | 说明 |
|---|---|
init |
在导入扩展后调用。 |
configure |
根据需要从函数代码中调用以配置扩展。 |
post_function_load_app_level |
在加载函数后立即调用。 函数名称和函数目录传递给扩展。 请记住,函数目录是只读目录,尝试写入此目录中的本地文件的任何操作都将失败。 |
pre_invocation_app_level |
在触发函数前立即调用。 函数上下文和函数调用参数传递给扩展。 通常可以传递上下文对象中的其他属性,以供函数代码使用。 |
post_invocation_app_level |
在函数执行完成后立即调用。 函数上下文、函数调用参数和调用返回对象将传递给扩展。 此实现是验证是否成功执行了生命周期挂钩的好方法。 |
函数级扩展
继承自特定函数触发器中的 FuncExtensionBase 运行的扩展。
FuncExtensionBase 公开以下抽象类方法以进行实现:
| 方法 | 说明 |
|---|---|
__init__ |
扩展的构造函数。 当在特定函数中初始化扩展实例时,将调用此方法。 实现此抽象方法时,可能需要接受 filename 参数,并将其传递给父级的方法 super().__init__(filename) 以进行适当的扩展注册。 |
post_function_load |
在加载函数后立即调用。 函数名称和函数目录传递给扩展。 请记住,函数目录是只读目录,尝试写入此目录中的本地文件的任何操作都将失败。 |
pre_invocation |
在触发函数前立即调用。 函数上下文和函数调用参数传递给扩展。 通常可以传递上下文对象中的其他属性,以供函数代码使用。 |
post_invocation |
在函数执行完成后立即调用。 函数上下文、函数调用参数和调用返回对象将传递给扩展。 此实现是验证是否成功执行了生命周期挂钩的好方法。 |
跨域资源共享
Azure Functions 支持跨域资源共享 (CORS)。 CORS 在门户中以及通过 Azure CLI 进行配置。 CORS 允许的来源列表应用于函数应用级别。 启用 CORS 后,响应包含 Access-Control-Allow-Origin 标头。 有关详细信息,请参阅 跨域资源共享。
Python 函数应用完全支持跨源资源共享 (CORS)。
异步
默认情况下,Python 的主机实例一次只能处理一个函数调用。 这是因为 Python 是单线程运行时。 对于处理大量 I/O 事件或受 I/O 约束的函数应用,可以通过异步运行函数来显著提高性能。 有关详细信息,请参阅在 Azure Functions 中提高 Python 应用的吞吐量性能。
共享内存(预览版)
为了提高吞吐量,Azure Functions 可以让你的进程外 Python 语言工作器与 Azure Functions 主机进程共享内存。 当函数应用遇到瓶颈时,可以通过添加名为 FUNCTIONS_WORKER_SHARED_MEMORY_DATA_TRANSFER_ENABLED 且值为 1 的应用程序设置来启用共享内存。 启用共享内存后,可以使用 DOCKER_SHM_SIZE 设置将共享内存设置为 268435456 之类的值,即相当于 256 MB。
例如,在使用 Blob 存储绑定传输大于 1 MB 的有效负载时,你可以启用共享内存以减少瓶颈。
此功能仅适用于在高级和专用(Azure 应用服务)计划中运行的函数应用。 要了解详细信息,请参阅共享内存。
已知问题和常见问题解答
下面是针对常见问题的两篇故障排除指南:
下面是针对 v2 编程模型已知问题的两篇故障排除指南:
所有已知问题和功能请求都将在 GitHub 问题列表进行跟踪。 如果你遇到 GitHub 中未列出的问题,请创建新问题并提供问题的详细说明。
后续步骤
有关详细信息,请参阅以下资源: