可以检查自定义语音模型的识别质量。 可以播放上传的音频,并确定提供的识别结果是否正确。 成功创建测试后,可以查看模型如何转录音频数据集,或并排比较两个模型的结果。
并行模型测试可用于验证哪个语音识别模型最适合应用程序。 有关需要听录文本数据集输入的准确性客观度量,请参阅以定量方式测试模型。
重要
测试时,系统将执行听录。 请务必记住,因为定价因服务套餐和订阅级别而异。 请始终参阅官方 Azure AI 服务定价 以获取最新详细信息。
创建测试
按照以下说明创建测试:
登录 Speech Studio。
导航到 Speech Studio>自定义语音 并从列表中选择项目名称。
选择 “测试模型>创建新测试”。
选择“ 检查质量”(仅音频数据)>下一步。
选择要用于测试的音频数据集,然后选择“ 下一步”。 如果没有任何可用的数据集,请取消设置,然后转到“语音数据集”菜单来上传数据集。
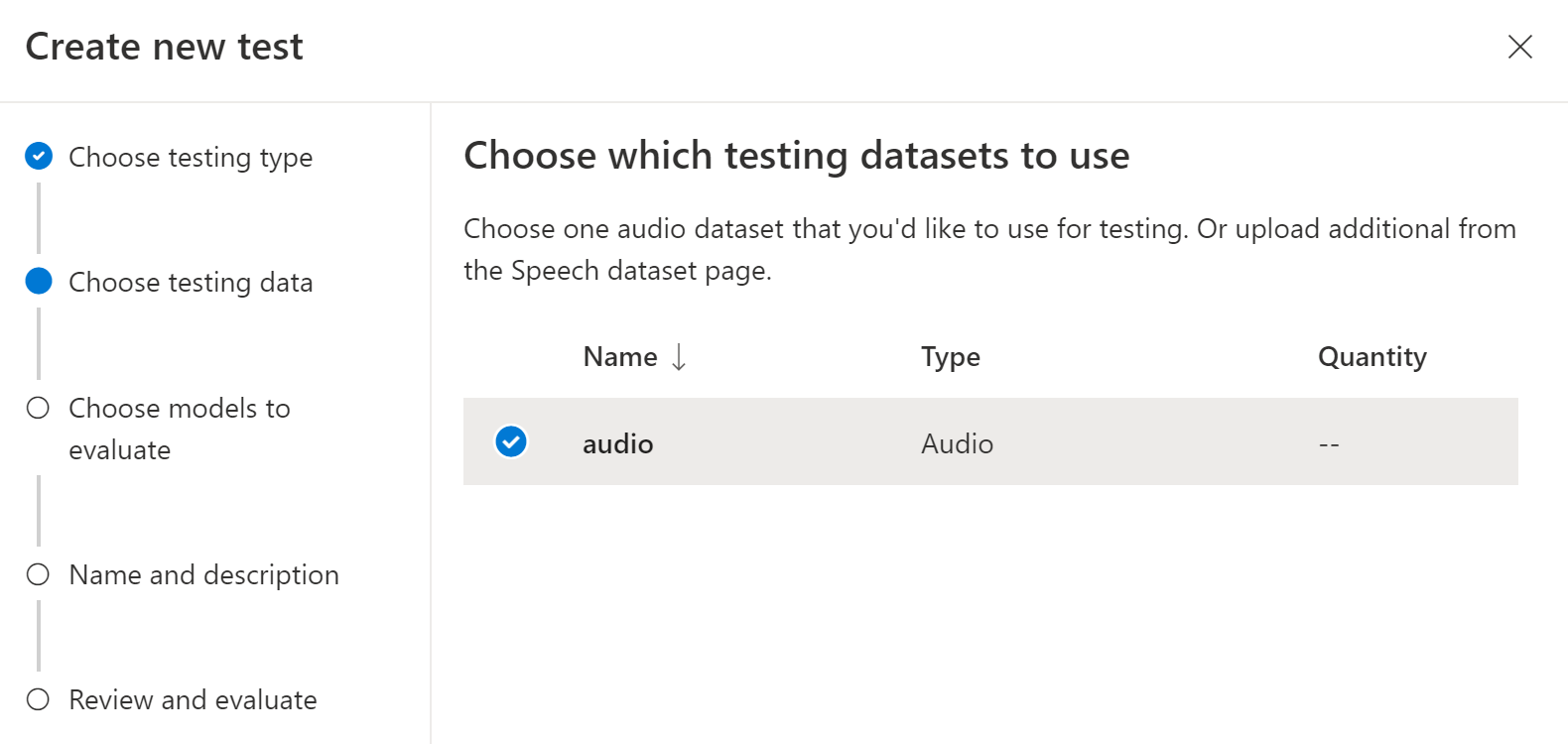
选择一两个模型来评估和比较准确性。
输入测试名称和说明,然后选择“ 下一步”。
检查你的设置,然后选择“保存并关闭”。
若要创建测试,请使用 spx csr evaluation create 命令。 根据以下说明构造请求参数:
- 将
project属性设置为现有项目的 ID。 建议使用此属性,以便还可以在 Speech Studio 中查看测试。 可以运行spx csr project list命令来获取可用项目。 - 将所需
model1属性设置为要测试的模型的 ID。 - 将所需
model2属性设置为要测试的另一个模型的 ID。 如果你不想比较两个模型,请对model1和model2使用相同的模型。 - 将所需
dataset属性设置为要用于测试的数据集的 ID。 - 设置
language属性,否则 Speech CLI 将默认设置为“en-US”。 此参数应设置为数据集内容的区域。 以后无法更改区域设置。 语音 CLIlanguage属性对应于 JSON 请求和响应中的locale属性。 - 设置所需的
name属性。 此参数是在 Speech Studio 中显示的名称。 语音 CLIname属性对应于 JSON 请求和响应中的displayName属性。
下面是创建测试的示例语音 CLI 命令:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
你应该会收到以下格式的响应正文:
{
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
响应正文中的顶级 self 属性是评估的 URI。 使用此 URI 获取有关项目和测试结果的详细信息。 还可以使用此 URI 更新或删除评估。
如需语音命令行界面的评估帮助,请运行以下命令:
spx help csr evaluation
若要创建测试,请使用语音转文本 REST API 的Evaluations_Create 操作。 根据以下说明构造请求正文:
- 将
project属性设置为现有项目的 URI。 建议使用此属性,以便还可以在 Speech Studio 中查看测试。 可以发出 Projects_List 请求来获取可用项目。 - 将所需
model1属性设置为要测试的模型的 URI。 - 将所需
model2属性设置为要测试的另一个模型的 URI。 如果你不想比较两个模型,请对model1和model2使用相同的模型。 - 将所需
dataset属性设置为要用于测试的数据集的 URI。 - 设置所需的
locale属性。 此属性应该是数据集内容的区域设置。 以后无法更改区域设置。 - 设置所需的
displayName属性。 此属性是在 Speech Studio 中显示的名称。
使用 URI 发出 HTTP POST 请求,如以下示例所示。 将 YourSubscriptionKey 替换为语音资源密钥,将 YourServiceRegion 替换为语音资源区域,并按前面所述设置请求正文属性。
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.azure.cn/speechtotext/v3.2/evaluations"
你应该会收到以下格式的响应正文:
{
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
响应正文中的顶级 self 属性是评估的 URI。 使用此 URI 获取 有关评估项目和测试结果的详细信息。 还可以使用此 URI 更新或删除评估。
获取测试结果
应该获取测试结果,并检查音频数据集,以比较每个模型的听录结果。
按照以下步骤获取测试结果:
- 登录 Speech Studio。
- 选择 “自定义语音> 项目名称 >测试模型”。
- 按测试名称选择链接。
- 测试完成后,状态指示为 “成功” 时,您应该会看到包含每个已测试模型的 WER 编号的结果。
此页面列出了数据集中所有的语句、识别结果,以及提交的数据集中的转录文件。 可以切换各种错误类型,包括插入、删除和替换。 通过侦听音频并比较每列中的识别结果,可以确定哪个模型满足你的需求,并确定需要更多训练和改进的位置。
若要获取测试结果,请使用 spx csr evaluation status 命令。 根据以下说明构造请求参数:
- 将所需的
evaluation属性设置为想要获取测试结果的评估的 ID。
下面是获取测试结果的示例语音 CLI 命令:
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
响应正文中会返回模型、音频数据集、听录和更多详细信息。
你应该会收到以下格式的响应正文:
{
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
如需语音命令行界面的评估帮助,请运行以下命令:
spx help csr evaluation
若要获取测试结果,请首先使用语音转文本 REST API 的Evaluations_Get操作。
使用 URI 提出 HTTP GET 请求,如以下示例所示。 将 YourEvaluationId 替换为您的评估 ID,将 YourSubscriptionKey 替换为您的语音资源密钥,将 YourServiceRegion 替换为您的语音资源区域。
curl -v -X GET "https://YourServiceRegion.api.cognitive.azure.cn/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
响应正文中会返回模型、音频数据集、听录和更多详细信息。
你应该会收到以下格式的响应正文:
{
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://chinanorth2.api.cognitive.azure.cn/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
将听录与音频进行比较
可以根据音频输入数据集检查每个模型测试的听录输出。 如果在测试中包含两个模型,可以并排比较其听录质量。
审查听录的质量:
- 登录 Speech Studio。
- 选择 “自定义语音> 项目名称 >测试模型”。
- 按测试名称选择链接。
- 在读取模型对应的听录文本时播放音频文件。
如果测试数据集包含多个音频文件,则表中会显示多行。 如果在测试中包含两个模型,则听录文本在并列的列中显示。 模型之间的听录差异以蓝色文本字体显示。
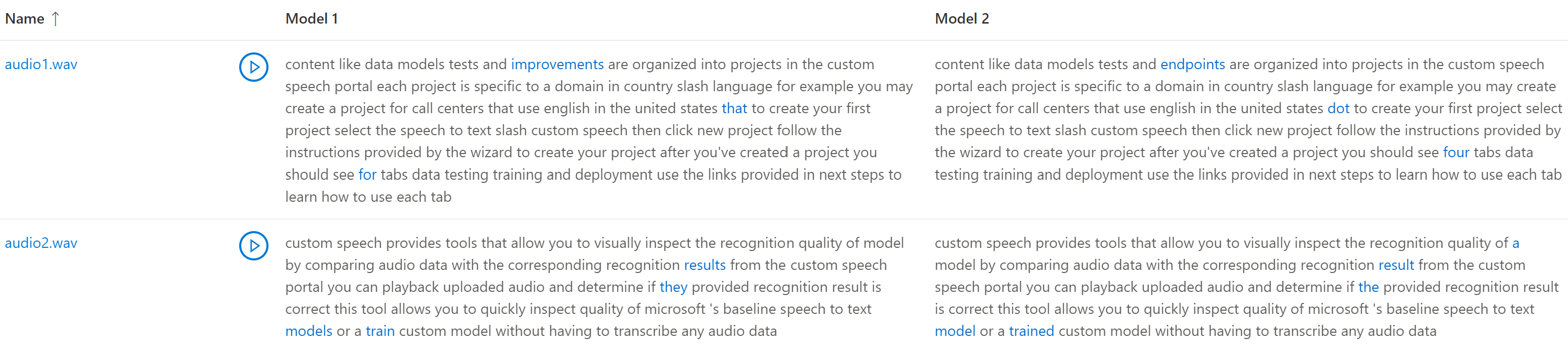
音频测试数据集、听录和测试的模型将在 测试结果中返回。 如果只测试了一个模型,则 model1 值匹配 model2,值 transcription1 匹配 transcription2。
评价转录文稿的质量:
- 下载音频测试数据集,除非已有副本。
- 下载输出转录文件。
- 播放音频文件的同时由模型读取相应的转录文本。
如果要比较两个模型之间的质量,请特别注意每个模型的听录之间的差异。
音频测试数据集、听录和测试的模型将在 测试结果中返回。 如果只测试了一个模型,则 model1 值匹配 model2,值 transcription1 匹配 transcription2。
审查听录的质量:
- 下载音频测试数据集,除非已有副本。
- 下载生成的转录文件。
- 在模型朗读对应文字稿时播放音频文件。
如果要比较两个模型之间的质量,请特别注意每个模型的听录之间的差异。