Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article describes reliability support in Azure Kubernetes Service (AKS). It addresses zone resiliency, availability zones, and multi-region deployments.
Production deployment recommendations
For recommendations on how to deploy reliable production workloads in AKS, see the following articles:
- Deployment and cluster reliability best practices for Azure Kubernetes Service (AKS)
- High availability and disaster recovery overview for Azure Kubernetes Service (AKS)
- Zone resiliency considerations for Azure Kubernetes Service (AKS)
Reliability architecture overview
When you create an AKS cluster, the Azure platform automatically creates and configures:
- A control plane with the API server, etcd, the scheduler, and other pods required to manage your workload.
- A system node pool to your subscription that hosts your add-ons and additional pods running in the kube-system namespace.
Once this initial node pool setup is complete, you can add or delete node pools for your own user workloads. Node pools are not managed for reliability by AKS, and you must ensure that your workloads are resilient to infrastructure failures.
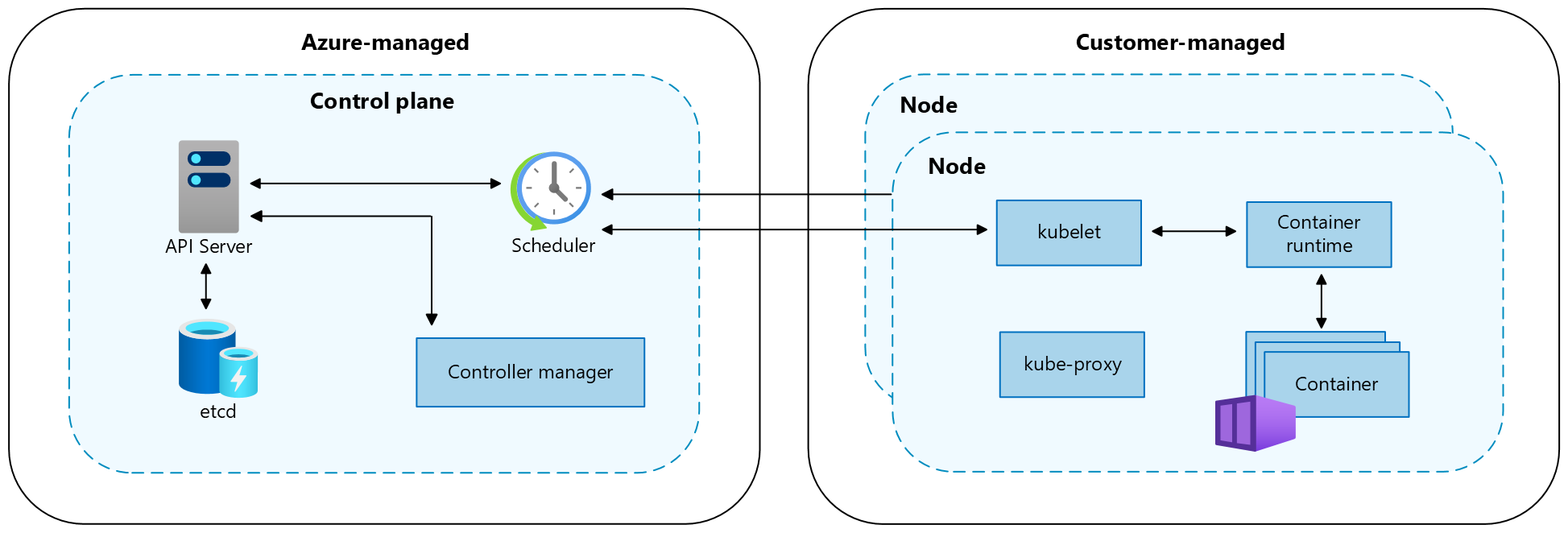
Resiliency is a shared responsibility between you and Microsoft. As a compute service, AKS has responsibility for some aspects of your cluster's reliability, but you have responsibility for other aspects:
- Azure assures the responsibility of managed components of AKS, like the AKS control plane.
- For components that AKS deploys and manages on your behalf, including node pools and load balancers attached to services, there's a dual responsibility. You need to define how the components should be configured to meet your reliability requirements, and Azure then deploys the components based on your requirements.
- Any components outside of the AKS cluster, including storage and databases, are your responsibility. You need to verify these components meet your reliability requirements. When you deploy your workloads, you need to ensure that the other Azure components are also configured for resiliency by following the best practices for those services.
Transient faults
Transient faults are short, intermittent failures in components. They occur frequently in a distributed environment like the cloud, and they're a normal part of operations. They correct themselves after a short period of time. It's important that your applications handle transient faults, usually by retrying affected requests.
All cloud-hosted applications should follow Azure's transient fault handling guidance when communicating with any cloud-hosted APIs, databases, and other components. To learn more about handling transient faults, see Recommendations for handing transient faults.
When you use AKS, transient faults can occur due to a variety of reasons, including application crashes, pod scaling and balancing operations, node patching, and temporary infrastructure failures such as hardware or networking issues.
Because it's not possible to eliminate all transient faults, clients that access your AKS hosted applications should be prepared to retry failed requests and follow other transient fault handling recommendations. Meanwhile, you can still minimize the likelihood of transient faults, as well as avoid or mitigate the downtime they might cause, by following Kubernetes and Azure best practices in your deployment, such as:
- Set Pod Disruption Budgets (PDBs) in your pod YAML to specify how many pods you need to have in a
Readystate at any given point of time. When set, AKS ensures the availability of minimum replicas when running operations to cordon and drain the nodes. If a PDB can't be satisfied during processes like upgrades, the pod continues to function and the operation might fail. For more information, see Pod Disruption Budgets (PDBs). - Use
maxUnavailableto define the maximum number of replicas that can become unavailable at any given point of time. As an example, if you're performing a rolling restart, AKS ensures that no more than themaxUnavailablenumber of pods are being churned at a given point of time. For more information, see maxUnavailable. - Follow deployment best practices. Pod replicas can also fail due to application issues. For more information about how to handle these issues, see the Deployment level best practices for AKS cluster reliability.
Note
If you want AKS to validate your deployments for adherence to best practices and provide blocking or warning notifications as necessary, you can use Deployment Safeguards (Preview), a managed offering which helps enforce product best practices before your code gets deployed to the cluster. For more information, see Use deployment safeguards to enforce best practices in Azure Kubernetes Service (AKS) (Preview).
Availability zone support
Availability zones are physically separate groups of datacenters within each Azure region. When one zone fails, services can fail over to one of the remaining zones.
For more information on availability zones in Azure, see What are availability zones?
When you deploy an AKS cluster into a region that supports availability zones, different components require different types of configuration.
The AKS control plane is zone resilient by default and doesn't require any configuration or management by you to achieve resiliency in the case of a zone failure. However, control plane resiliency isn't sufficient for your cluster to remain operational in the event of a zone failure. For the system node pool and any user node pools that you deploy, you must enable availability zone support to ensure that your workloads are resilient to availability zone failures.
Region support
Zone-resilient AKS clusters can be deployed into any region that supports availability zones.
Considerations
To enhance the reliability and resiliency of AKS production workloads in a region, you'll need to configure AKS for zone redundancy by making the following configurations:
- Deploy multiple replicas: Kubernetes spreads your pods across nodes based on node labels. To spread your workload across zones, you need to make sure that you deploy multiple replicas of your pod. For instance, if you configure the node pool with three zones, but only deploy a single replica of your pod, your deployment won't be zone resilient.
- Enable automatic scaling: Kubernetes node pools provide manual and automatic scaling options. With manual scaling, you can add or delete nodes as needed, and pending pods wait until you scale up a node pool. With AKS managed scaling (using the cluster autoscaler or node autoprovisioning (NAP)), AKS scales the node pool based on pod needs within your subscription's SKU quota and capacity. This ensures that your pods are scheduled on available nodes in the up zones.
- Set pod topology constraints: Use pod topology spread constraints to control how pods are spread across different nodes or zones. This helps you achieve high availability and resiliency and efficient resource utilization. If you prefer to strictly spread across zones, you can set them to force a pod into a pending state to maintain the balance of pods across zones. For more information, see Pod topology spread constraints.
- Configure zone resilient networking: If your pods serve external traffic, configure your cluster network architecture using services like Azure Application Gateway v2, Standard Load Balancer, or Azure Front Door .
- Ensure dependencies are zone resilient: Most AKS applications use other services for storage, security, or networking. Make sure you review the zone resiliency recommendations for those services as well.
Cost
There's no additional charge to enable availability zone support in AKS. You pay for the virtual machines (VMs) and other resources that you deploy in the availability zones.
Configure availability zone support
- Create a new AKS cluster with availability zone support: To configure availability zone support, see Create an Azure Kubernetes Service (AKS) cluster that uses availability zones.
- Migration: You can't enable availability zone support after you create a cluster. Instead, you need to create a new cluster with availability zone support enabled and delete the old one.
- Disable availability zone support: You can't disable availability zone support after you create a cluster. Instead, you need to create a new cluster with availability zone support disabled and delete the old one.
Normal operations
Traffic routing between zones: When you deploy an AKS cluster that uses availability zones, it's important to ensure that your networking components are also zone-resilient. Depending on the load balancers and other networking components you use, you might need to explicitly configure them to route traffic to the correct nodes in the correct zones and to respond to zone outages. To learn more, see Zone resiliency considerations for Azure Kubernetes Service (AKS).
Data replication between zones: If you're running a stateless workload, you should use managed Azure services, such Azure databases, Azure Cache for Redis, or Azure Storage to store the application data. Using these services ensures your traffic can be moved across nodes and zones without risking data loss or impacting the user experience. You can use Kubernetes Deployments, Services, and Health Probes to manage stateless pods and ensure even distribution across zones.
If you need to store state within your cluster by using Azure disks, use Azure zone-redundant storage (ZRS) to ensure that your data is replicated across multiple availability zones. For more information, see Choose the right disk type based on application needs.
Zone-down experience
Detection and response: In the event of a zone outage, the control plane automatically fails over. If your node pools use availability zones and follow zone resiliency best practices, you can expect AKS to bring up nodes and replicas in the zones that are up and running. This is done automatically when using managed solutions like cluster autoscaler or NAP. Without autoscaling, they remain in the Pending state and wait for manual intervention to scale up the node pool. AKS also attempts to rebalance the pods across the healthy zones. If you choose to manually scale your node pool in a zone down scenario, your pods might be left in the Pending state when there are no nodes available in the healthy zones. Along with this, scaling out in the remaining zones is also subject to the availability of quota and capacity for the VM SKU you use.
Notification: AKS doesn't currently notify you when a zone is down. You can use your node or pod health metrics to monitor the health of your nodes and pods.
Active requests: Any active requests might experience disruptions. Some requests can fail, and latency might increase while your workload fails over to another zone.
Expected data loss: If you store state within your cluster by using Azure disks, and you use zone-redundant storage, then a zone failure isn't expected to cause any data loss.
Expected downtime: If you've correctly configured zone resiliency for your cluster and pods, then a zone failure isn't expected to cause downtime to your AKS workload. To learn more, see Zone resiliency considerations for Azure Kubernetes Service (AKS).
Traffic rerouting: Load balancers are responsible for rerouting new incoming requests to pods running on healthy nodes. To learn more, see Zone resiliency considerations for Azure Kubernetes Service (AKS).
Failback
When the availability zone recovers, failback behavior differs depending on the component:
- Control plane: AKS automatically restores control plane operations across all availability zones. No manual intervention is required.
- Node pools and nodes: Immediately after failback, nodes remain in the previously healthy zones and don't get restored into the recovered zone. However, the next time a node scaling operation is performed, such as when you scale out your node pool, the node pool can create nodes in the recovered zone.
- Pods: Immediately after failback, pods continue to run on the nodes they are already running on. When new pods are created or existing pods are recreated, they are eligible to use nodes in the recovered zone.
- Storage: Any storage attached to pods recovers based on how zone-redundant storage works.
Testing for zone failures
You can test your resiliency to availability zone failures using the following methods:
- Cordon and drain nodes in a single availability zone
- Simulate an availability zone failure using Azure Chaos Studio
Multi-region support
AKS clusters are single-region resources. If the region is unavailable, your AKS cluster is also unavailable.
Alternative multi-region approaches
If you need to deploy your Kubernetes workload to multiple Azure regions, you have two categories of options to manage the orchestration of these clusters:
- Azure Kubernetes Fleet Manager (Fleet) offers a simple and more managed experience. With Fleet, you can:
- Manage a set of AKS clusters as a single unit, and those clusters can be distributed across multiple Azure regions.
- Automate certain aspects of cluster management, such as cluster and node image upgrades.
- Use Fleet traffic distribution capabilities to spread traffic across the clusters and automatically fail over if a region is unavailable.
- Orchestrate failover with a manual active-active or active-passive deployment model if your workload requires more nuanced control over the different components of inter-region failovers. For more information, see High availability and disaster recovery overview for Azure Kubernetes Service (AKS).
Backups
With Azure Backup, you can use a backup extension to back up AKS cluster resources and persistent volumes attached to the cluster. The Backup vault communicates with the AKS cluster through the extension to perform backup and restore operations.
If your AKS cluster is in a region with a pair, you can configure backups to be stored in geo-redundant storage. You can restore geo-redundant backups into the paired region.
For more information, see the following articles:
For most solutions, you shouldn't rely exclusively on backups. Instead, use the other capabilities described in this guide to support your resiliency requirements, and strive to use stateless clusters that minimize the need for backup. Store data in external storage systems and databases instead of within your cluster.
If you maintain state in your cluster, backups protect against some risks that other approaches don't. For more information, see What are redundancy, replication, and backup?
Service-level agreement
The service-level agreement (SLA) for Azure Logic Apps describes the expected availability of the service. This agreement also describes the conditions to meet for achieving this expectation. To understand these conditions, make sure that you review the Service Level Agreements (SLA) for Online Services.
AKS offers three pricing tiers for cluster management: Free, Standard, and Premium. For more information, see Free, Standard, and Premium pricing tiers for Azure Kubernetes Service (AKS) cluster management. The Free tier enables you to use AKS to test your workloads. The Standard and Premium tiers are designed for production workloads. When you deploy an AKS cluster with availability zones enabled, the uptime percentage defined in the SLA increases. However, you're only covered by the SLA if you deploy a cluster in the Standard or Premium pricing tiers.