Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
了解如何在使用 Azure Databricks 和自动化 ML 的 Azure 机器学习中配置开发环境。
Azure Databricks非常适合用于在 Azure 云中可缩放的 Apache Spark 平台上运行大规模的密集型机器学习工作流。 它提供基于 Notebook 的协作环境,其中包含基于 CPU 或 GPU 的计算群集。
有关其他机器学习开发环境的信息,请参阅设置 Python 开发环境。
先决条件
Azure 机器学习工作区。 若要创建一个,请使用创建工作区资源一文中的步骤。
Azure Databricks 与 Azure 机器学习和 AutoML
Azure Databricks 与 Azure 机器学习及其 AutoML 功能集成。
可以将 Azure Databricks:
- 用于训练模型(通过 Spark MLlib),并将该模型部署到 ACI/AKS。
- 与自动化机器学习功能配合使用(通过使用 Azure 机器学习 SDK)。
- 用作 Azure 机器学习管道中的计算目标。
设置 Databricks 群集
创建 Databricks 群集。 仅当在 Databricks 上安装适用于自动化机器学习的 SDK 时,某些设置才适用。
创建群集需要几分钟时间。
使用以下设置:
| 设置 | 适用于 | Value |
|---|---|---|
| 群集名称 | 通用 | yourclustername |
| Databricks 运行时版本 | 通用 | 9.1 LTS |
| Python 版本 | 通用 | 3 |
| 辅助角色类型 (确定最大并发迭代数) |
自动化机器学习 (仅限) |
首选内存优化的 VM |
| 工作节点 | 通用 | 2 个或以上 |
| 启用自动缩放 | 自动化机器学习 (仅限) |
取消选中 |
请等待群集运行完成,然后继续操作。
将 Azure 机器学习 SDK 添加到 Databricks
群集运行后,请创建一个库用于将相应的 Azure 机器学习 SDK 包附加到群集。
若要使用自动化 ML,请跳到添加带有 AutoML 的 Azure 机器学习 SDK。
右键单击用于存储该库的当前工作区文件夹。 选择“创建”>“库”。
提示
如果使用的是旧版 SDK,请从群集的已安装库中取消选择该版本,并将其移到垃圾桶中。 安装新的 SDK 版本并重启群集。 如果重启后出现问题,请分离并重新附加群集。
选择以下选项(不支持任何其他 SDK 安装)
SDK 包附加内容 源 PyPi 名称 对于 Databricks 上传 Python Egg 或 PyPI azureml-sdk[databricks] 警告
无法安装其他 SDK 附加项。 请仅选择 [
databricks] 选项。- 不要选择“自动附加到所有群集”。
- 选择群集名称旁边的“附加”。
监视错误,直到状态更改为“已附加”。这可能需要几分钟时间。 如果此步骤失败:
请尝试通过以下操作重启群集:
- 在左窗格中,选择“群集”。
- 在表中选择你的群集名称。
- 在“库”选项卡上,选择“重启”。
安装成功后,屏幕将如下所示:
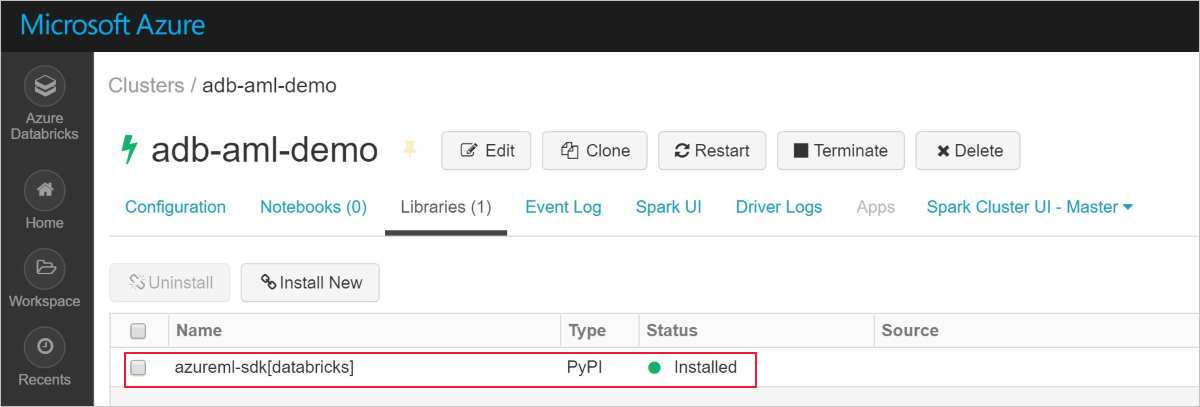
将带有 AutoML 的 Azure 机器学习 SDK 添加到 Databricks
如果群集是使用 Databricks Runtime 7.3 LTS(而不是 ML)创建的,请在笔记本的第一个单元格中运行以下命令以安装 Azure 机器学习 SDK。
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
AutoML 配置设置
在 AutoML 配置中使用 Azure Databricks 时添加以下参数:
max_concurrent_iterations基于群集中的工作器节点数。spark_context=sc基于默认的 Spark 上下文。
适用于 Azure Databricks 的 ML 笔记本
尝试以下操作:
尽管有许多示例笔记本可用,但只有这些示例笔记本适用于 Azure Databricks。
直接从工作区导入这些示例。 请参阅下文:
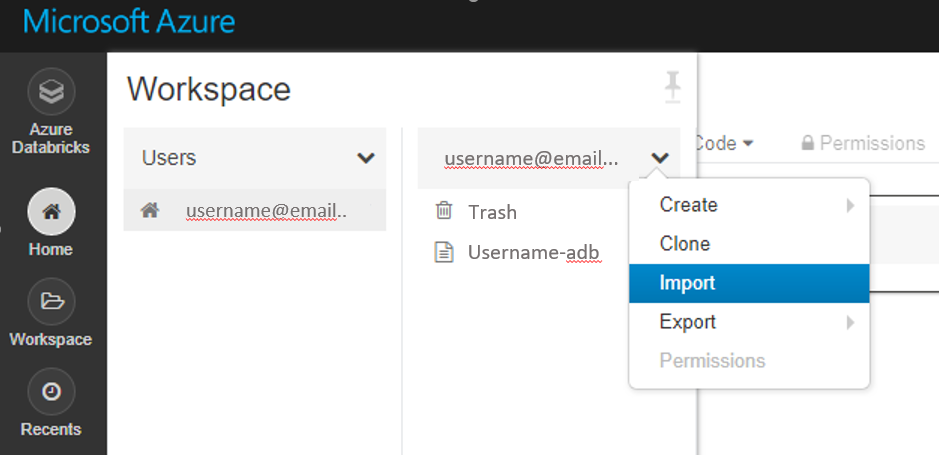
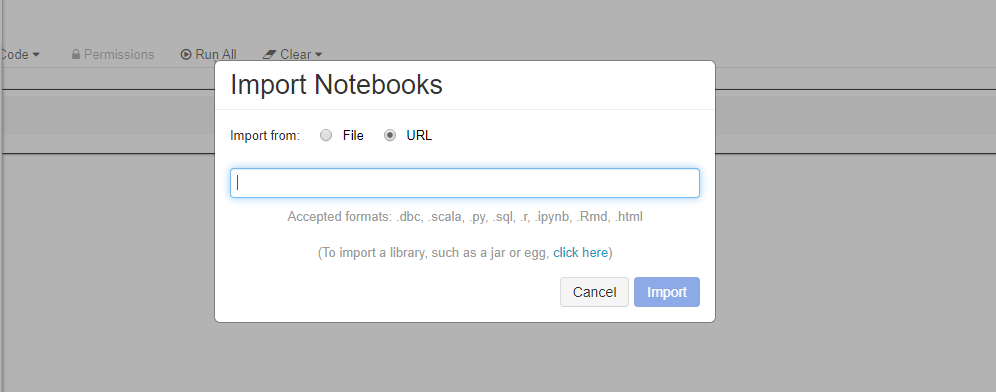
疑难解答
Databricks 取消自动化机器学习运行:在 Azure Databricks 上使用自动化机器学习功能时,若要取消某个运行并启动新的试验运行,请重启 Azure Databricks 群集。
Databricks 自动化机器学习的迭代数超过 10 个:在自动化机器学习设置中,如果迭代数超过 10 个,请在提交运行时将
show_output设置为False。Databricks Azure 机器学习 SDK 和自动化机器学习的小组件:Databricks 笔记本不支持 Azure 机器学习 SDK 小组件,因为笔记本无法分析 HTML 小组件。 可以通过在 Azure Databricks 笔记本单元中使用以下 Python 代码,在门户中查看该小组件:
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))安装包时失败
安装更多包时,Azure Databricks 上的 Azure 机器学习 SDK 安装失败。 某些包(如
psutil)可能会导致冲突。 为了避免安装错误,请通过冻结库版本来安装包。 此问题与 Databricks 相关,而与 Azure 机器学习 SDK 无关。 使用其他库时也可能会遇到此问题。 示例:psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0或者,如果一直面临 Python 库的安装问题,可以使用初始化脚本。 此方法并不正式受到支持。 有关详细信息,请参阅群集范围的初始化脚本。
导入错误: 无法从
pandas._libs.tslibs中导入名称Timedelta:如果在使用自动机器学习时看到此错误,请在笔记本中运行以下两行:%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4导入错误:没有名为“pandas.core.indexes”的模块:如果在使用自动化机器学习时看到此错误:
请运行以下命令,在 Azure Databricks 群集中安装两个包:
scikit-learn==0.19.1 pandas==0.22.0分离群集,然后将其重新附加到笔记本。
如果这些步骤无法解决问题,请尝试重启群集。
FailToSendFeather:如果在 Azure Databricks 群集上读取数据时出现
FailToSendFeather错误,请参考以下解决方法:- 将
azureml-sdk[automl]包升级到最新版本。 - 添加
azureml-dataprep版本 1.1.8 或更高版本。 - 添加
pyarrow版本 0.11 或更高版本。
- 将
后续步骤
- 在 Azure 机器学习中使用 MNIST 数据集来训练和部署模型。
- 请参阅适用于 Python 的 Azure 机器学习 SDK 参考。