Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Python SDK azure-ai-ml v2 (current)
Python SDK azure-ai-ml v2 (current)
In this article, learn how to run your TensorFlow training scripts at scale using Azure Machine Learning Python SDK v2.
The example code in this article train a TensorFlow model to classify handwritten digits, using a deep neural network (DNN); register the model; and deploy it to an online endpoint.
Whether you're developing a TensorFlow model from the ground-up or you're bringing an existing model into the cloud, you can use Azure Machine Learning to scale out open-source training jobs using elastic cloud compute resources. You can build, deploy, version, and monitor production-grade models with Azure Machine Learning.
Prerequisites
To benefit from this article, you need to:
- Access an Azure subscription. If you don't have one already, create a trial subscription.
- Run the code in this article using either an Azure Machine Learning compute instance or your own Jupyter notebook.
- Azure Machine Learning compute instance—no downloads or installation necessary
- Complete the Create resources to get started tutorial to create a dedicated notebook server preloaded with the SDK and the sample repository.
- In the samples deep learning folder on the notebook server, find a completed and expanded notebook by navigating to this directory: v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow.
- Your Jupyter notebook server
- Azure Machine Learning compute instance—no downloads or installation necessary
- Download the following files:
- training script tf_mnist.py
- scoring script score.py
- sample request file sample-request.json
You can also find a completed Jupyter Notebook version of this guide on the GitHub samples page.
Before you can run the code in this article to create a GPU cluster, you'll need to request a quota increase for your workspace.
Set up the job
This section sets up the job for training by loading the required Python packages, connecting to a workspace, creating a compute resource to run a command job, and creating an environment to run the job.
Connect to the workspace
First, you need to connect to your Azure Machine Learning workspace. The Azure Machine Learning workspace is the top-level resource for the service. It provides you with a centralized place to work with all the artifacts you create when you use Azure Machine Learning.
We're using DefaultAzureCredential to get access to the workspace. This credential should be capable of handling most Azure SDK authentication scenarios.
If DefaultAzureCredential doesn't work for you, see azure-identity reference documentation or Set up authentication for more available credentials.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
If you prefer to use a browser to sign in and authenticate, you should uncomment the following code and use it instead.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Next, get a handle to the workspace by providing your Subscription ID, Resource Group name, and workspace name. To find these parameters:
- Look for your workspace name in the upper-right corner of the Azure Machine Learning studio toolbar.
- Select your workspace name to show your Resource Group and Subscription ID.
- Copy the values for Resource Group and Subscription ID into the code.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
The result of running this script is a workspace handle that you use to manage other resources and jobs.
Note
- Creating
MLClientwill not connect the client to the workspace. The client initialization is lazy and will wait for the first time it needs to make a call. In this article, this will happen during compute creation.
Create a compute resource
Azure Machine Learning needs a compute resource to run a job. This resource can be single or multi-node machines with Linux or Windows OS, or a specific compute fabric like Spark.
In the following example script, we provision a Linux compute cluster. You can see the Azure Machine Learning pricing page for the full list of VM sizes and prices. Since we need a GPU cluster for this example, let's pick a STANDARD_NC6 model and create an Azure Machine Learning compute.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)
Create a job environment
To run an Azure Machine Learning job, you need an environment. An Azure Machine Learning environment encapsulates the dependencies (such as software runtime and libraries) needed to run your machine learning training script on your compute resource. This environment is similar to a Python environment on your local machine.
Azure Machine Learning allows you to either use a curated (or ready-made) environment—useful for common training and inference scenarios—or create a custom environment using a Docker image or a Conda configuration.
In this article, you reuse the curated Azure Machine Learning environment AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu. You use the latest version of this environment using the @latest directive.
curated_env_name = "AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu@latest"
Configure and submit your training job
In this section, we begin by introducing the data for training. We then cover how to run a training job, using a training script that we've provided. You learn to build the training job by configuring the command for running the training script. Then, you submit the training job to run in Azure Machine Learning.
Obtain the training data
You'll use data from the Modified National Institute of Standards and Technology (MNIST) database of handwritten digits. This data is sourced from Yan LeCun's website and stored in an Azure storage account.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
For more information about the MNIST dataset, visit Yan LeCun's website.
Prepare the training script
In this article, we've provided the training script tf_mnist.py. In practice, you should be able to take any custom training script as is and run it with Azure Machine Learning without having to modify your code.
The provided training script does the following:
- handles the data preprocessing, splitting the data into test and train data;
- trains a model, using the data; and
- returns the output model.
During the pipeline run, you use MLFlow to log the parameters and metrics. To learn how to enable MLFlow tracking, see Track ML experiments and models with MLflow.
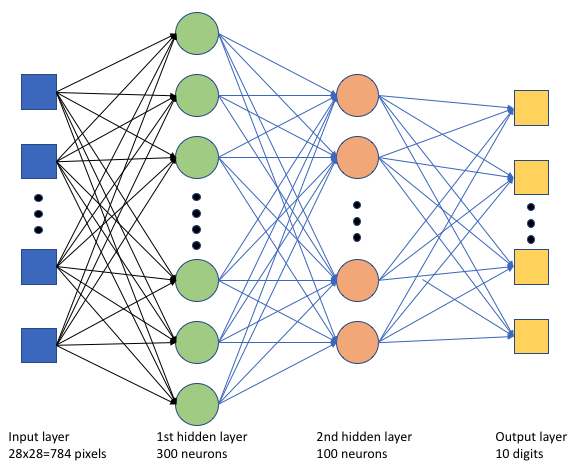
In the training script tf_mnist.py, we create a simple deep neural network (DNN). This DNN has:
- An input layer with 28 * 28 = 784 neurons. Each neuron represents an image pixel.
- Two hidden layers. The first hidden layer has 300 neurons and the second hidden layer has 100 neurons.
- An output layer with 10 neurons. Each neuron represents a targeted label from 0 to 9.
Build the training job
Now that you have all the assets required to run your job, it's time to build it using the Azure Machine Learning Python SDK v2. For this example, we are creating a command.
An Azure Machine Learning command is a resource that specifies all the details needed to execute your training code in the cloud. These details include the inputs and outputs, type of hardware to use, software to install, and how to run your code. The command contains information to execute a single command.
Configure the command
You use the general purpose command to run the training script and perform your desired tasks. Create a Command object to specify the configuration details of your training job.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)
The inputs for this command include the data location, batch size, number of neurons in the first and second layer, and learning rate. Notice that we've passed in the web path directly as an input.
For the parameter values:
- provide the compute cluster
gpu_compute_target = "gpu-cluster"that you created for running this command; - provide the curated environment
curated_env_namethat you declared earlier; - configure the command line action itself—in this case, the command is
python tf_mnist.py. You can access the inputs and outputs in the command via the${{ ... }}notation; and - configure metadata such as the display name and experiment name; where an experiment is a container for all the iterations one does on a certain project. All the jobs submitted under the same experiment name would be listed next to each other in Azure Machine Learning studio.
- provide the compute cluster
In this example, you'll use the
UserIdentityto run the command. Using a user identity means that the command will use your identity to run the job and access the data from the blob.
Submit the job
It's now time to submit the job to run in Azure Machine Learning. This time, you'll use create_or_update on ml_client.jobs.
ml_client.jobs.create_or_update(job)
Once completed, the job will register a model in your workspace (as a result of training) and output a link for viewing the job in Azure Machine Learning studio.
Warning
Azure Machine Learning runs training scripts by copying the entire source directory. If you have sensitive data that you don't want to upload, use a .ignore file or don't include it in the source directory.
What happens during job execution
As the job is executed, it goes through the following stages:
Preparing: A docker image is created according to the environment defined. The image is uploaded to the workspace's container registry and cached for later runs. Logs are also streamed to the job history and can be viewed to monitor progress. If a curated environment is specified, the cached image backing that curated environment will be used.
Scaling: The cluster attempts to scale up if it requires more nodes to execute the run than are currently available.
Running: All scripts in the script folder src are uploaded to the compute target, data stores are mounted or copied, and the script is executed. Outputs from stdout and the ./logs folder are streamed to the job history and can be used to monitor the job.
Tune model hyperparameters
Now that you've seen how to do a TensorFlow training run using the SDK, let's see if you can further improve the accuracy of your model. You can tune and optimize your model's hyperparameters using Azure Machine Learning's sweep capabilities.
To tune the model's hyperparameters, define the parameter space in which to search during training. You'll do this by replacing some of the parameters (batch_size, first_layer_neurons, second_layer_neurons, and learning_rate) passed to the training job with special inputs from the azure.ml.sweep package.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)
Then, you configure sweep on the command job, using some sweep-specific parameters, such as the primary metric to watch and the sampling algorithm to use.
In the following code, we use random sampling to try different configuration sets of hyperparameters in an attempt to maximize our primary metric, validation_acc.
We also define an early termination policy—the BanditPolicy. This policy operates by checking the job every two iterations. If the primary metric, validation_acc, falls outside the top 10 percent range, Azure Machine Learning terminates the job. This saves the model from continuing to explore hyperparameters that show no promise of helping to reach the target metric.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)
Now, you can submit this job as before. This time, you'll be running a sweep job that sweeps over your train job.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)
You can monitor the job by using the studio user interface link that is presented during the job run.
Find and register the best model
Once all the runs complete, you can find the run that produced the model with the highest accuracy.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)
You can then register this model.
registered_model = ml_client.models.create_or_update(model=model)
Deploy the model as an online endpoint
After you register your model, you can deploy it as an online endpoint—that is, as a web service in the Azure cloud.
To deploy a machine learning service, you typically need:
- The model assets that you want to deploy. These assets include the model's file and metadata that you already registered in your training job.
- Some code to run as a service. The code executes the model on a given input request (an entry script). This entry script receives data submitted to a deployed web service and passes it to the model. After the model processes the data, the script returns the model's response to the client. The script is specific to your model and must understand the data that the model expects and returns. When you use an MLFlow model, Azure Machine Learning automatically creates this script for you.
For more information about deployment, see Deploy and score a machine learning model with managed online endpoint using Python SDK v2.
Create a new online endpoint
As a first step to deploying your model, you need to create your online endpoint. The endpoint name must be unique in the entire Azure region. For this article, you create a unique name using a universally unique identifier (UUID).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Once you create the endpoint, you can retrieve it as follows:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Deploy the model to the endpoint
After you've created the endpoint, you can deploy the model with the entry script. An endpoint can have multiple deployments. Using rules, the endpoint can then direct traffic to these deployments.
In the following code, you create a single deployment that handles 100% of the incoming traffic. We use an arbitrary color name (tff-blue) for the deployment. You could also use any other name such as tff-green or tff-red for the deployment. The code to deploy the model to the endpoint does the following:
- deploys the best version of the model that you registered earlier;
- scores the model, using the
score.pyfile; and - uses the same curated environment (that you declared earlier) to perform inferencing.
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Note
Expect this deployment to take a bit of time to finish.
Test the deployment with a sample query
After you deploy the model to the endpoint, you can predict the output of the deployed model, using the invoke method on the endpoint. To run the inference, use the sample request file sample-request.json from the request folder.
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request.json",
deployment_name="tff-blue",
)
You can then print the returned predictions and plot them along with the input images. Use red font color and inverted image (white on black) to highlight the misclassified samples.
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()
Note
Because the model accuracy is high, you might have to run the cell a few times before seeing a misclassified sample.
Clean up resources
If you won't be using the endpoint, delete it to stop using the resource. Make sure no other deployments are using the endpoint before you delete it.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Note
Expect this cleanup to take a bit of time to finish.
Next steps
In this article, you trained and registered a TensorFlow model. You also deployed the model to an online endpoint. See these other articles to learn more about Azure Machine Learning.