APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
In this article, you learn how to import data into the Azure Machine Learning platform from external sources. A successful data import automatically creates and registers an Azure Machine Learning data asset with the name provided during that import. An Azure Machine Learning data asset resembles a web browser bookmark (favorites). You don't need to remember long storage paths (URIs) that point to your most-frequently used data. Instead, you can create a data asset, and then access that asset with a friendly name.
A data import creates a cache of the source data, along with metadata, for faster and reliable data access in Azure Machine Learning training jobs. The data cache avoids network and connection constraints. The cached data is versioned to support reproducibility. This provides versioning capabilities for data imported from SQL Server sources. Additionally, the cached data provides data lineage for auditing tasks. A data import uses ADF (Azure Data Factory pipelines) behind the scenes, which means that users can avoid complex interactions with ADF. Behind the scenes, Azure Machine Learning also handles management of ADF compute resource pool size, compute resource provisioning, and tear-down, to optimize data transfer by determining proper parallelization.
The transferred data is partitioned and securely stored as parquet files in Azure storage. This enables faster processing during training. ADF compute costs only involve the time used for data transfers. Storage costs only involve the time needed to cache the data, because cached data is a copy of the data imported from an external source. Azure storage hosts that external source.
The caching feature involves upfront compute and storage costs. However, it pays for itself, and can save money, because it reduces recurring training compute costs, compared to direct connections to external source data during training. It caches data as parquet files, which makes job training faster and more reliable against connection timeouts for larger data sets. This leads to fewer reruns, and fewer training failures.
You can import data from Amazon S3, Azure SQL, and Snowflake.
Important
This feature is currently in public preview. This preview version is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities.
For more information, see Supplemental Terms of Use for Azure Previews.
Prerequisites
To create and work with data assets, you need:
Note
For a successful data import, please verify that you installed the latest azure-ai-ml package (version 1.15.0 or later) for SDK, and the ml extension (version 2.15.1 or later).
If you have an older SDK package or CLI extension, please remove the old one and install the new one with the code shown in the tab section. Follow the instructions for SDK and CLI as shown here:
Code versions
az extension remove -n ml
az extension add -n ml --yes
az extension show -n ml #(the version value needs to be 2.15.1 or later)
pip install azure-ai-ml
pip show azure-ai-ml #(the version value needs to be 1.15.0 or later)
Import from an external database as a mltable data asset
Note
The external databases can have Snowflake, Azure SQL, etc. formats.
The following code samples can import data from external databases. The connection that handles the import action determines the external database data source metadata. In this sample, the code imports data from a Snowflake resource. The connection points to a Snowflake source. With a little modification, the connection can point to an Azure SQL database source and an Azure SQL database source. The imported asset type from an external database source is mltable.
Create a YAML file <file-name>.yml:
$schema: http://azureml/sdk-2-0/DataImport.json
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# Datastore: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
type: mltable
name: <name>
source:
type: database
query: <query>
connection: <connection>
path: <path>
Next, run the following command in the CLI:
> az ml data import -f <file-name>.yml
from azure.ai.ml.entities import DataImport
from azure.ai.ml.data_transfer import Database
from azure.ai.ml import MLClient
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
ml_client = MLClient.from_config()
data_import = DataImport(
name="<name>",
source=Database(connection="<connection>", query="<query>"),
path="<path>"
)
ml_client.data.import_data(data_import=data_import)
Note
The example seen here describes the process for a Snowflake database. However, this process covers other external database formats, like Azure SQL, etc.
Navigate to the Azure Machine Learning studio.
Under Assets in the left navigation, select Data. Next, select the Data Import tab. Then select Create, as shown in this screenshot:
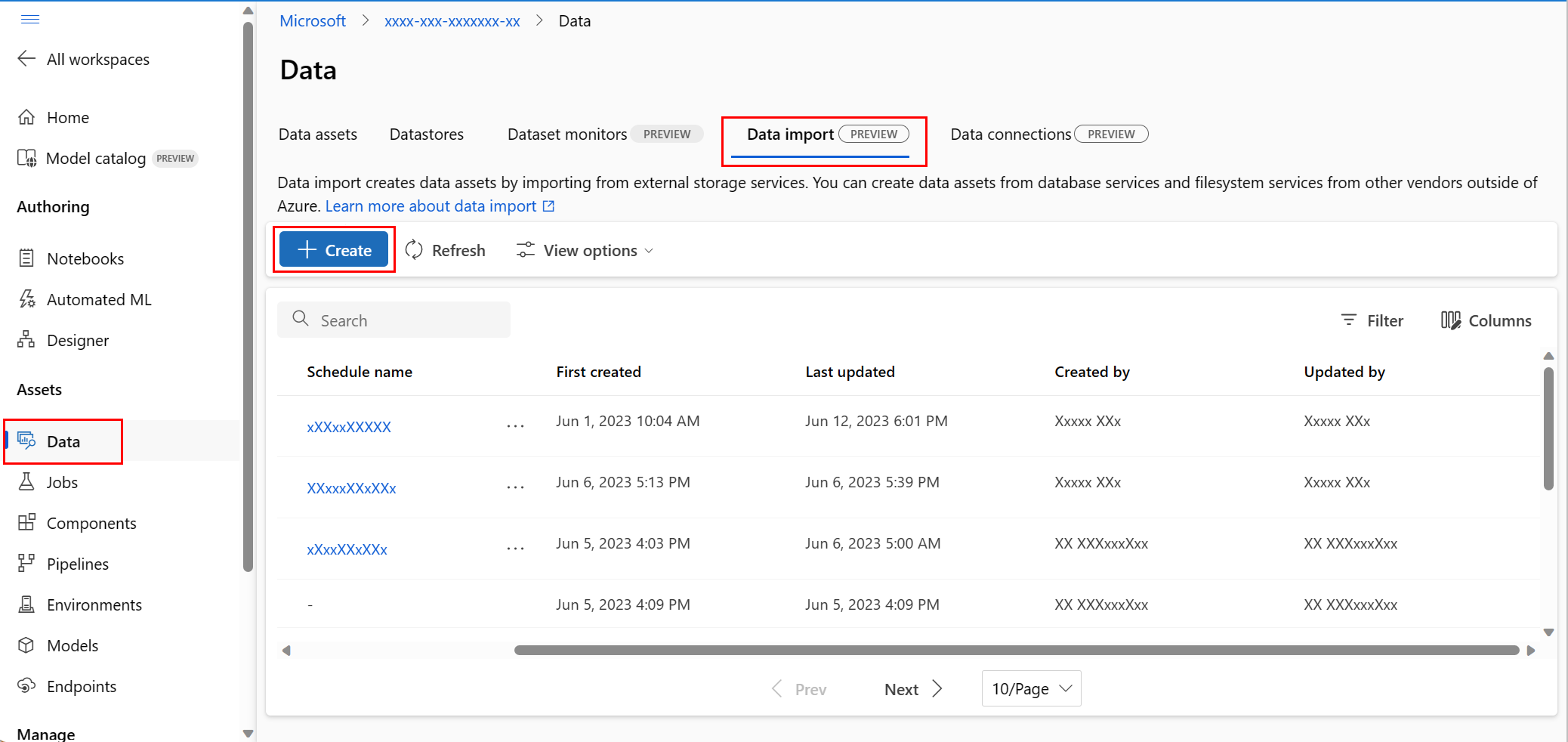
At the Data Source screen, select Snowflake, and then select Next, as shown in this screenshot:
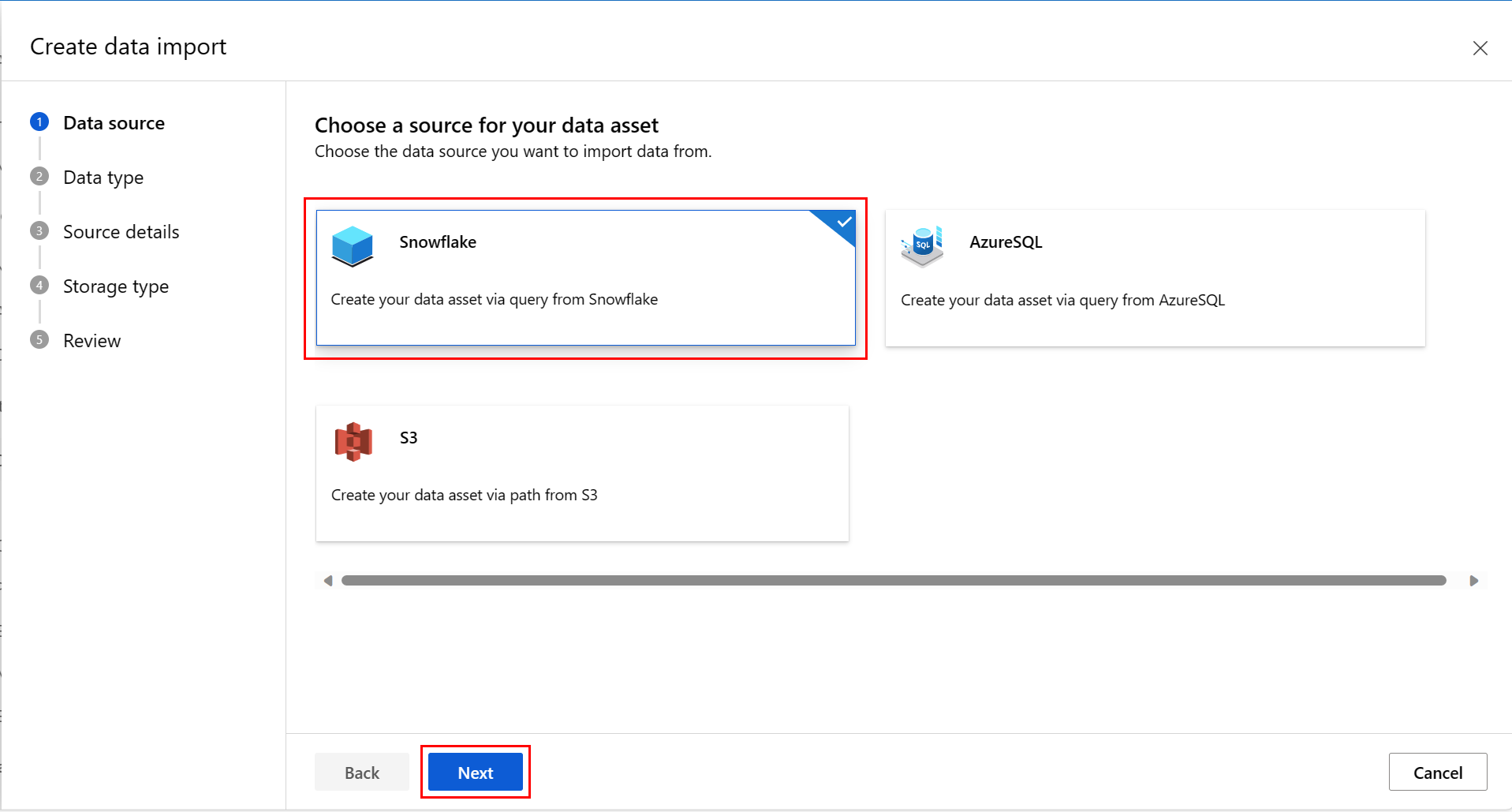
At the Data Type screen, fill in the values. The Type value defaults to Table (mltable). Then select Next, as shown in this screenshot:

At the Create data import screen, fill in the values, and select Next, as shown in this screenshot:
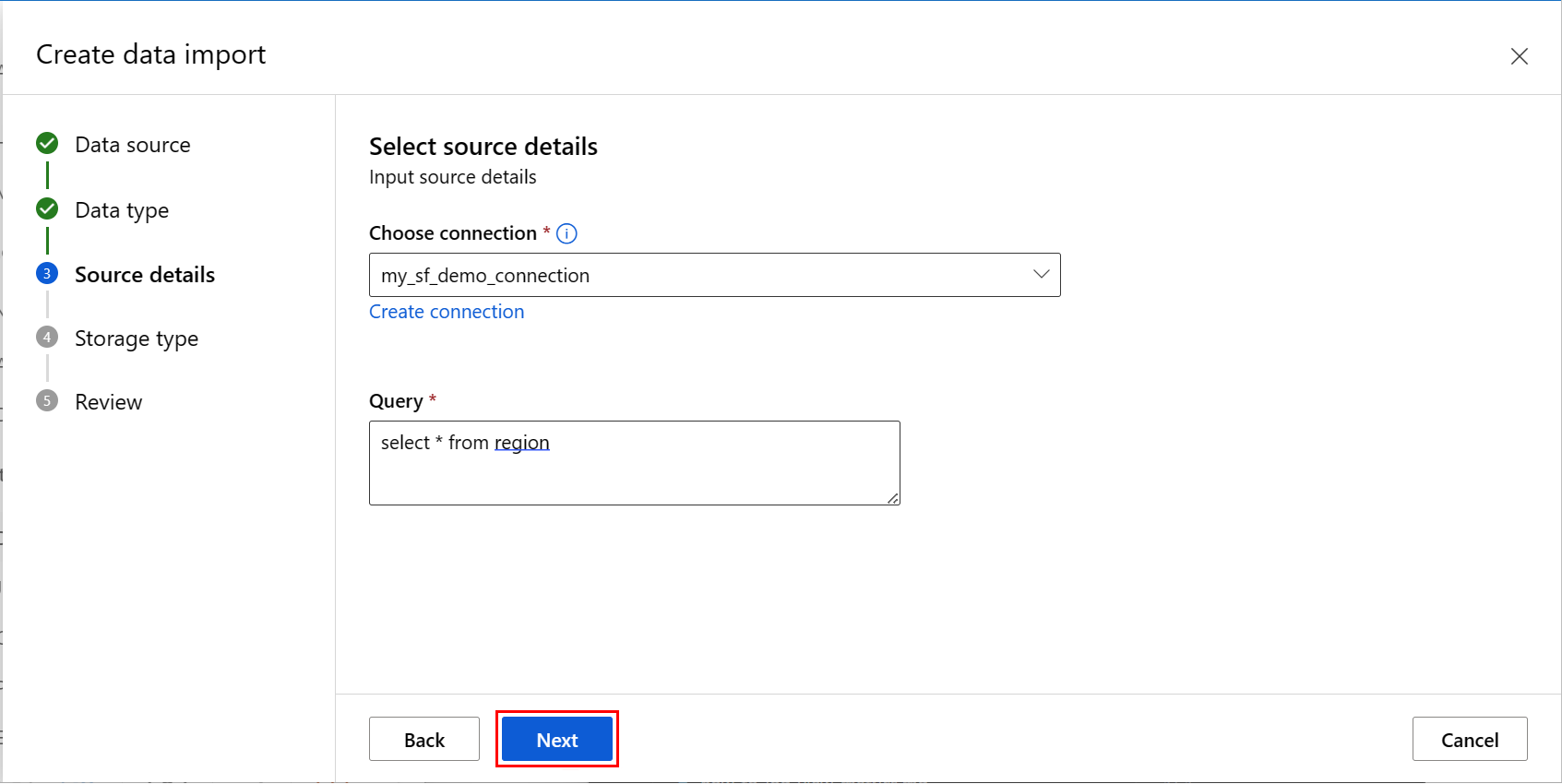
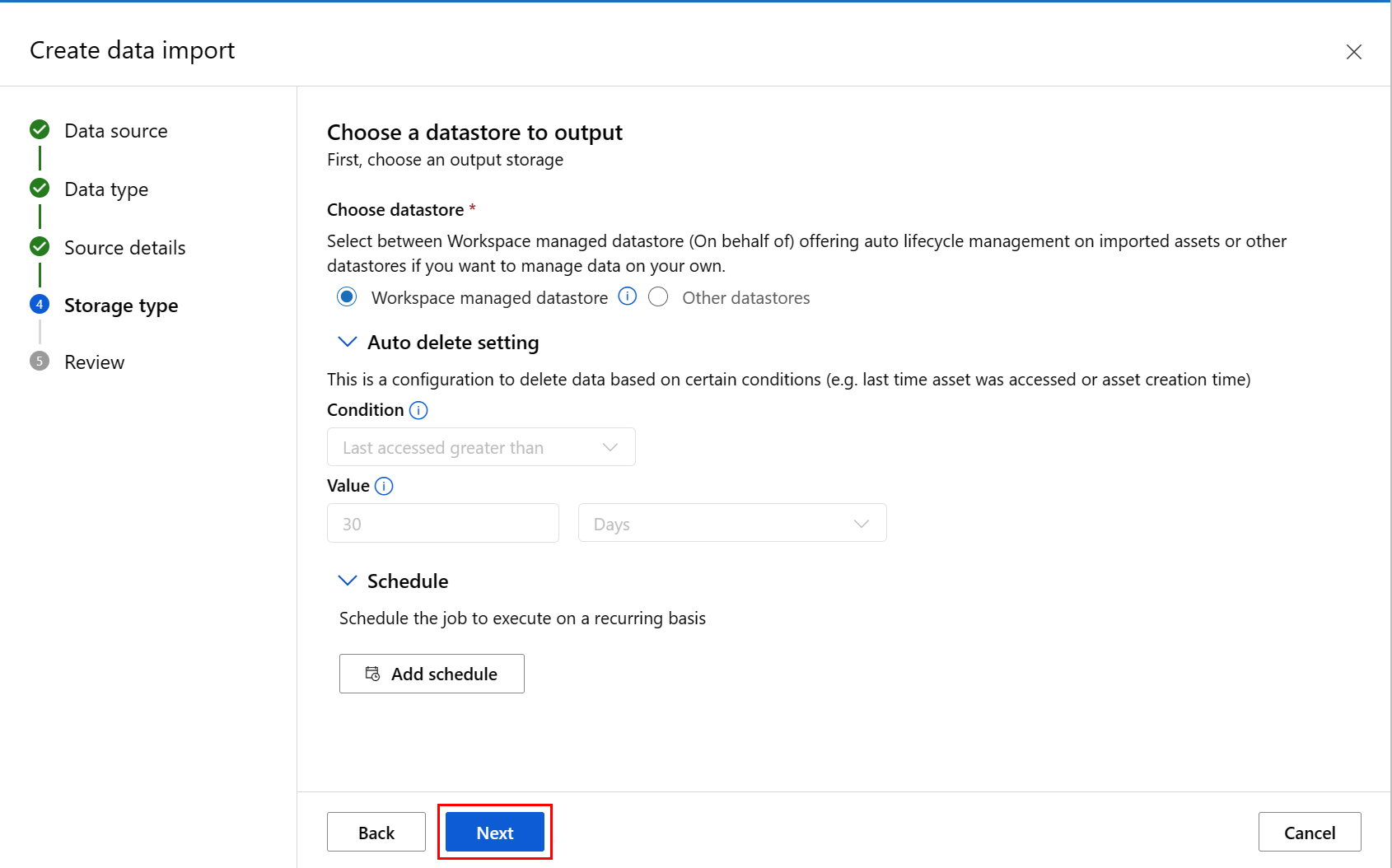
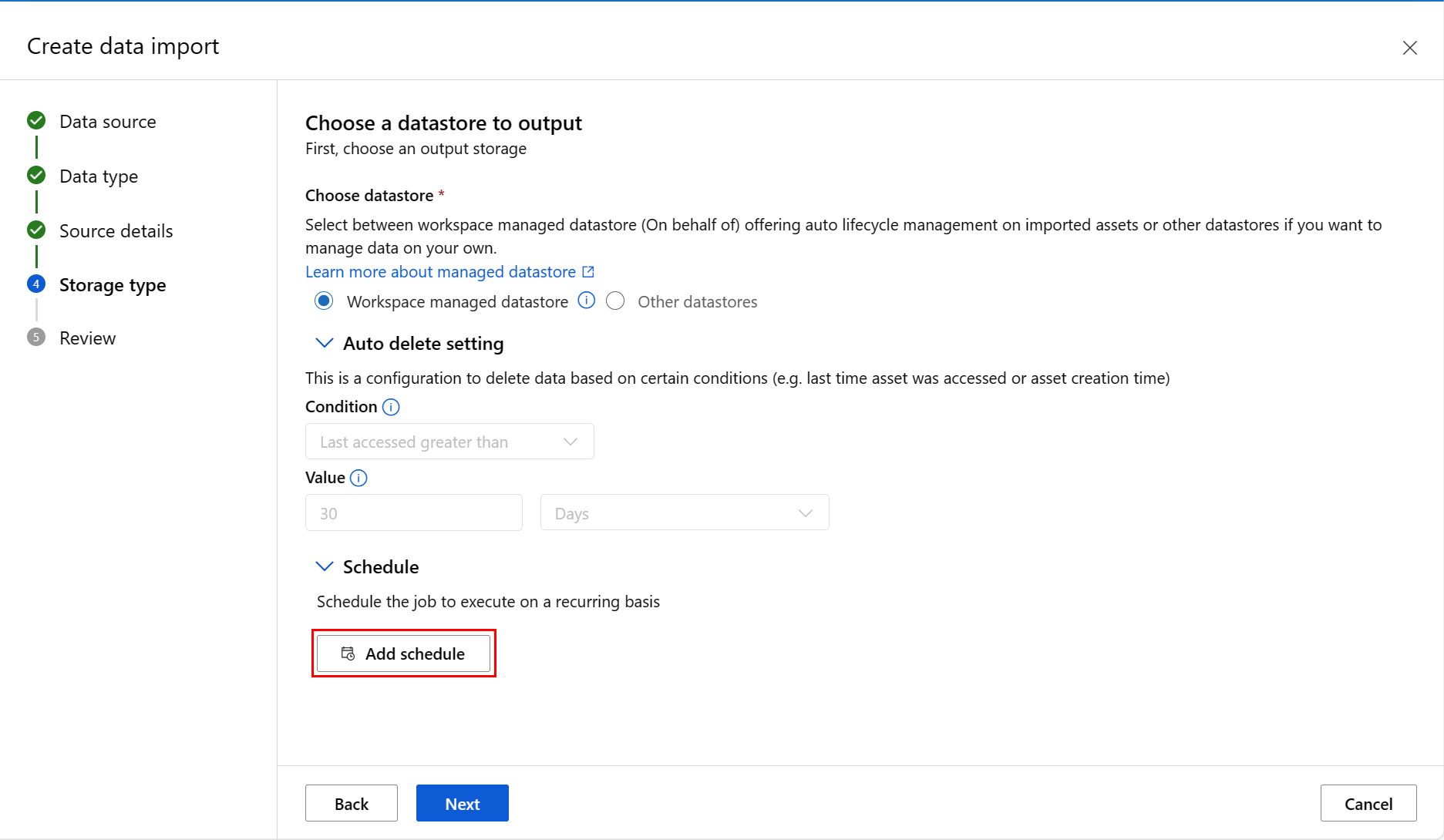
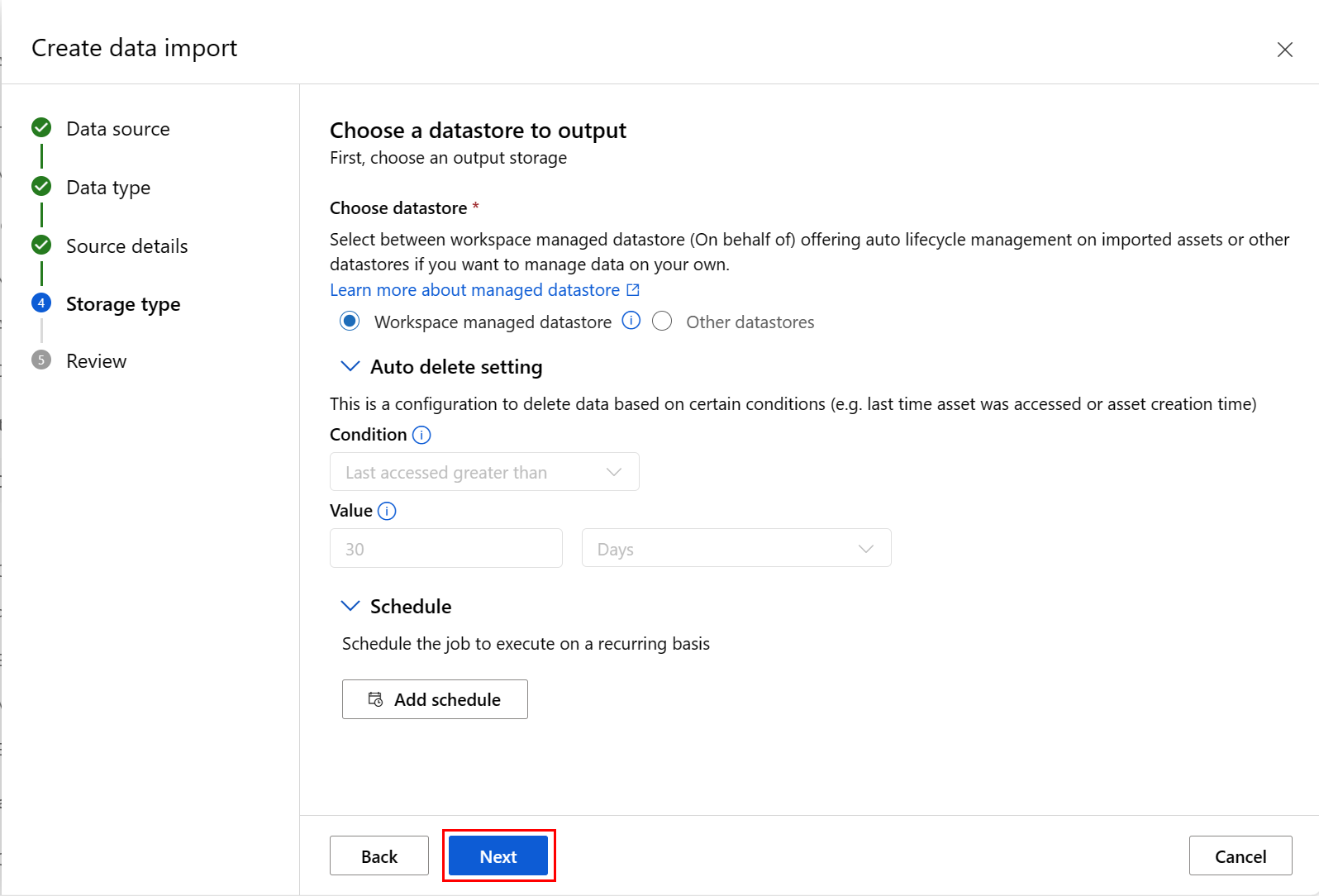
Fill in the values at the Choose a datastore to output screen, and select Next, as shown in this screenshot. Workspace managed datastore is selected by default; the path is automatically assigned by the system when you choose manged datastore. If you select Workspace managed datastore, the Auto delete setting dropdown appears. It offers a data deletion time window of 30 days by default, and how to manage imported data assets explains how to change this value.
Note
To choose your own datastore, select Other datastores. In that case, you must select the path for the location of the data cache.
You can add a schedule. Select Add schedule as shown in this screenshot:
A new panel opens, where you can define either a Recurrence schedule, or a Cron schedule. This screenshot shows the panel for a Recurrence schedule:
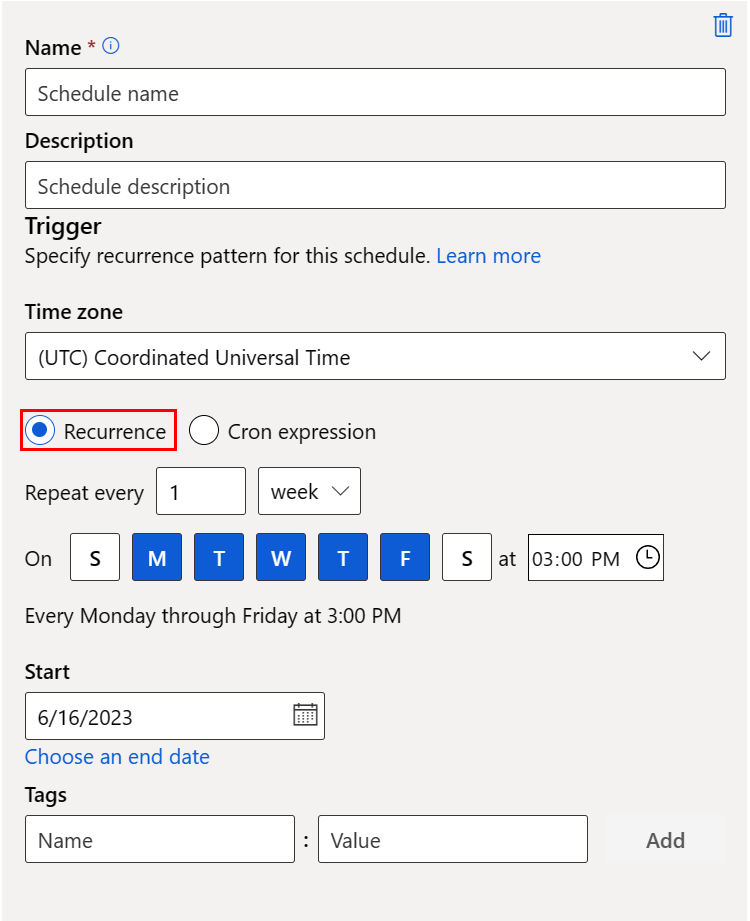
- Name: the unique identifier of the schedule within the workspace.
- Description: the schedule description.
- Trigger: the recurrence pattern of the schedule, which includes the following properties.
- Time zone: the trigger time calculation is based on this time zone; (UTC) Coordinated Universal Time by default.
- Recurrence or Cron expression: select recurrence to specify the recurring pattern. Under Recurrence, you can specify the recurrence frequency - by minutes, hours, days, weeks, or months.
- Start: the schedule first becomes active on this date. By default, the creation date of this schedule.
- End: the schedule will become inactive after this date. By default, it's NONE, which means that the schedule will always be active until you manually disable it.
- Tags: the selected schedule tags.
Note
Start specifies the start date and time with the timezone of the schedule. If start is omitted, the start time equals the schedule creation time. For a start time in the past, the first job runs at the next calculated run time.
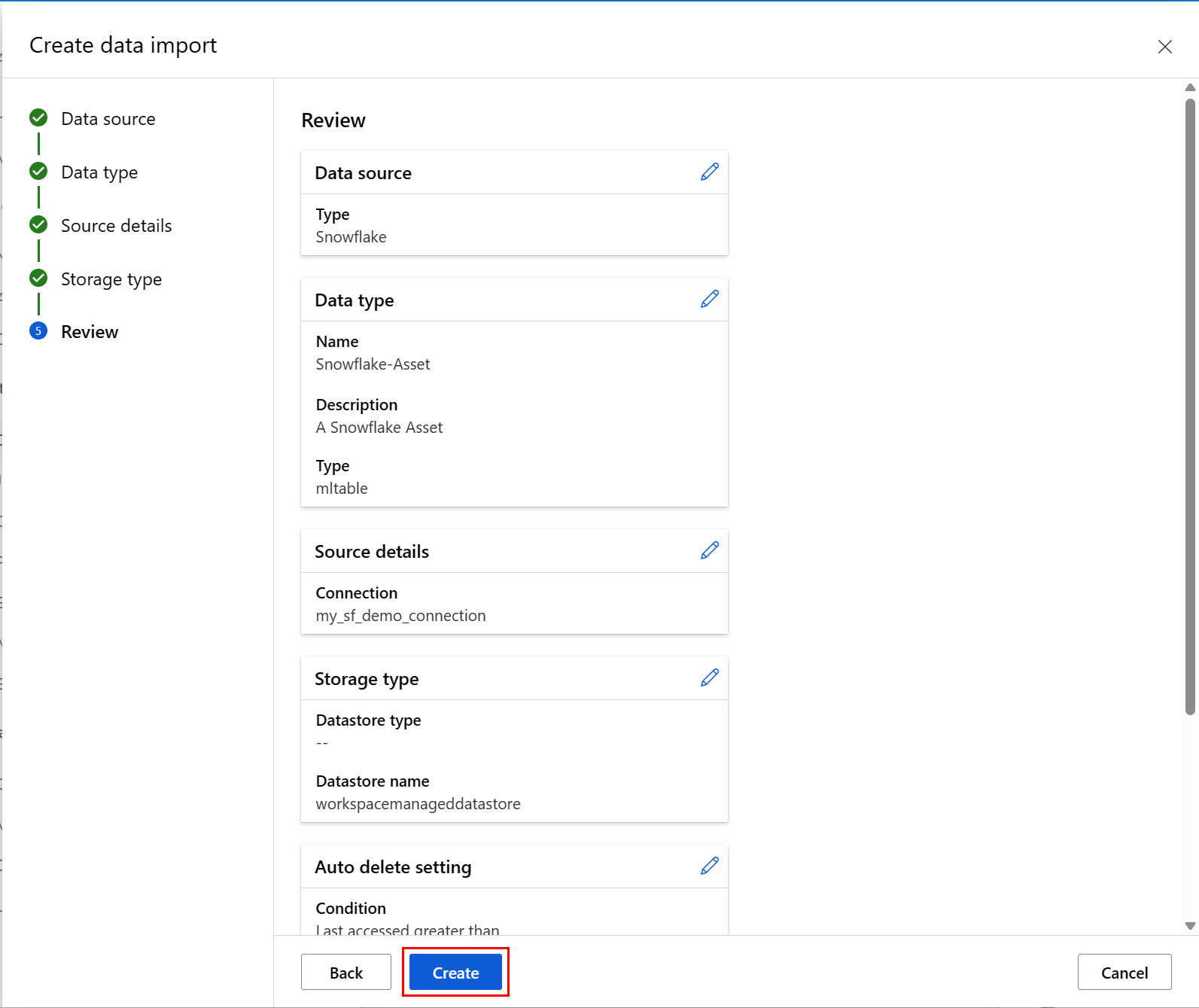
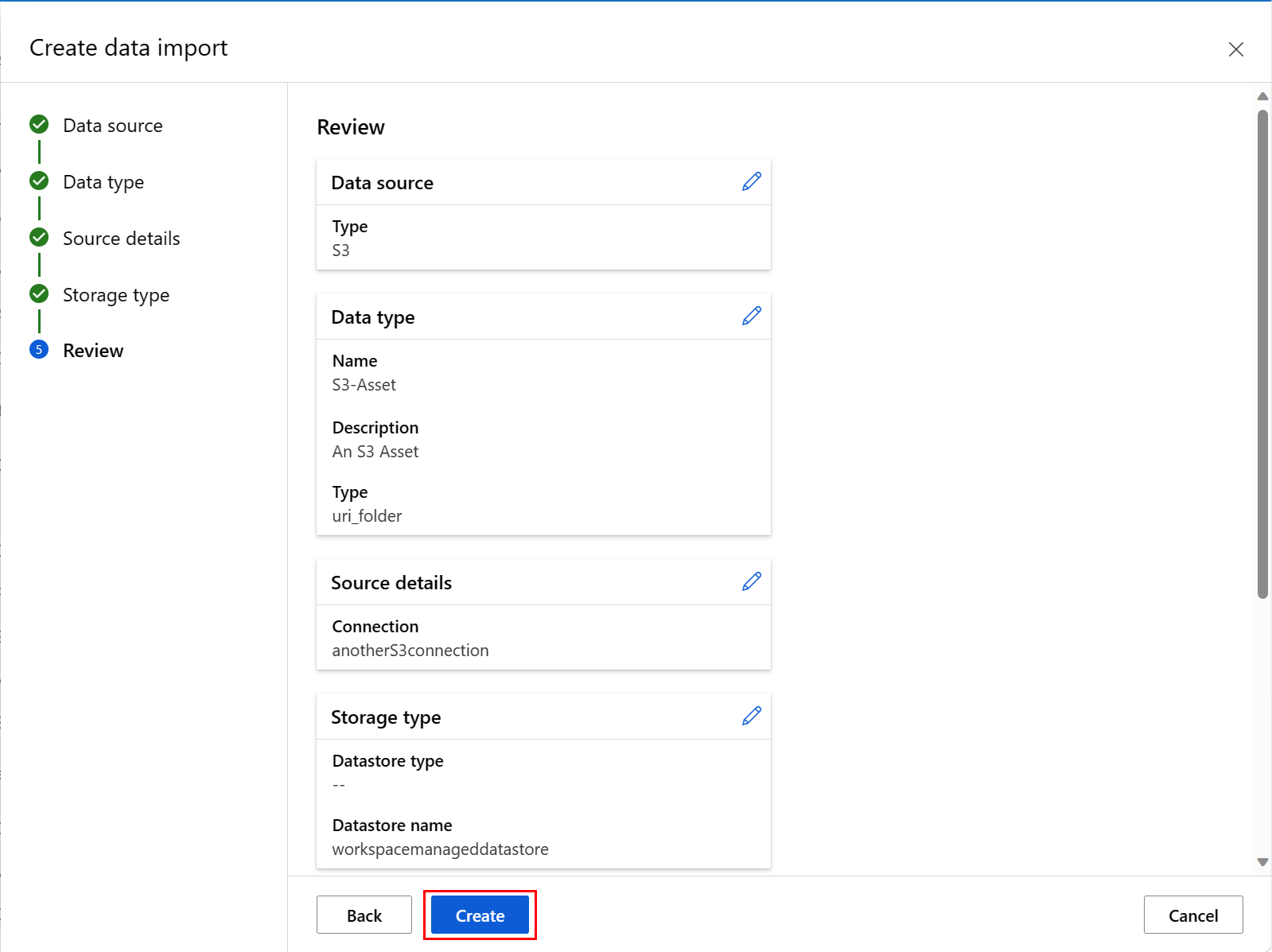
The next screenshot shows the last screen of this process. Review your choices, and select Create. At this screen, and the other screens in this process, select Back to move to earlier screens to change your choices of values.
This screenshot shows the panel for a Cron schedule:
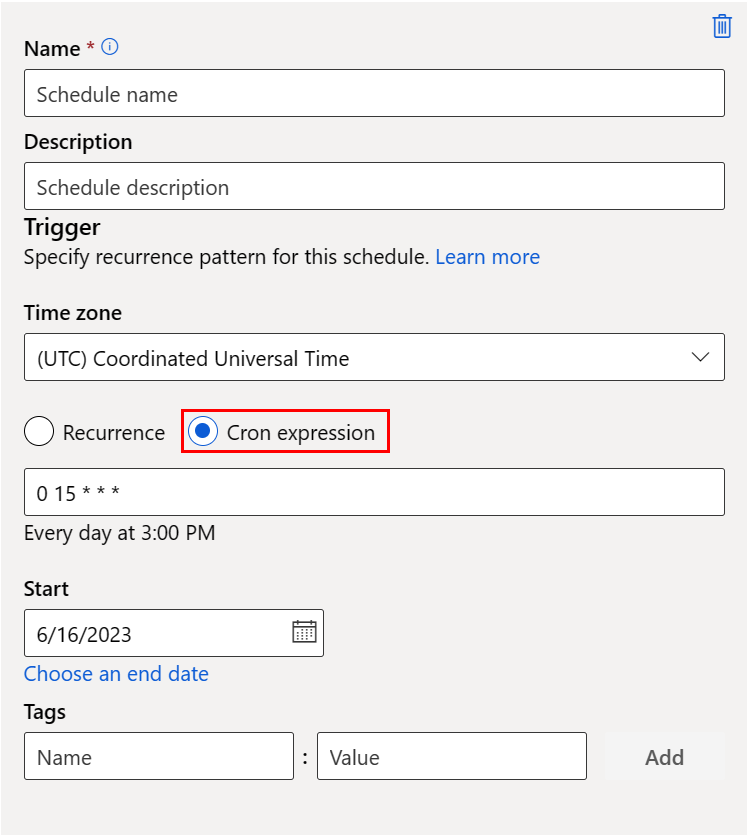
Name: the unique identifier of the schedule within the workspace.
Description: the schedule description.
Trigger: the recurrence pattern of the schedule, which includes the following properties.
Time zone: the trigger time calculation is based on this time zone; (UTC) Coordinated Universal Time by default.
Recurrence or Cron expression: select cron expression to specify the cron details.
(Required) expression uses a standard crontab expression to express a recurring schedule. A single expression is composed of five space-delimited fields:
MINUTES HOURS DAYS MONTHS DAYS-OF-WEEK
A single wildcard (*), which covers all values for the field. A *, in days, means all days of a month (which varies with month and year).
The expression: "15 16 * * 1" in the sample above means the 16:15PM on every Monday.
The next table lists the valid values for each field:
| Field |
Range |
Comment |
MINUTES |
0-59 |
- |
HOURS |
0-23 |
- |
DAYS |
- |
Not supported. The value is ignored and treated as *. |
MONTHS |
- |
Not supported. The value is ignored and treated as *. |
DAYS-OF-WEEK |
0-6 |
Zero (0) means Sunday. Names of days also accepted. |
For more information about crontab expressions, visit the Crontab Expression wiki on GitHub.
Important
DAYS and MONTH are not supported. If you pass one of these values, it will be ignored and treated as *.
- Start: the schedule first becomes active on this date. By default, the creation date of this schedule.
- End: the schedule will become inactive after this date. By default, it's NONE, which means that the schedule will always be active until you manually disable it.
- Tags: the selected schedule tags.
Note
Start specifies the start date and time with the timezone of the schedule. If start is omitted, the start time equals the schedule creation time. For a start time in the past, the first job runs at the next calculated run time.
The next screenshot shows the last screen of this process. Review your choices, and select Create. At this screen, and the other screens in this process, select Back to move to earlier screens to change your choices of values.
Import data from an external file system as a folder data asset
Note
An Amazon S3 data resource can serve as an external file system resource.
The connection that handles the data import action determines the aspects of the external data source. The connection defines an Amazon S3 bucket as the target. The connection expects a valid path value. An asset value imported from an external file system source has a type of uri_folder.
The next code sample imports data from an Amazon S3 resource.
Create a YAML file <file-name>.yml:
$schema: http://azureml/sdk-2-0/DataImport.json
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
type: uri_folder
name: <name>
source:
type: file_system
path: <path_on_source>
connection: <connection>
path: <path>
Next, execute this command in the CLI:
> az ml data import -f <file-name>.yml
from azure.ai.ml.entities import DataImport
from azure.ai.ml.data_transfer import FileSystem
from azure.ai.ml import MLClient
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
ml_client = MLClient.from_config()
data_import = DataImport(
name="<name>",
source=FileSystem(connection="<connection>", path="<path_on_source>"),
path="<path>"
)
ml_client.data.import_data(data_import=data_import)
Navigate to the Azure Machine Learning studio.
Under Assets in the left navigation, select Data. Next, select the Data Import tab. Then select Create as shown in this screenshot:
At the Data Source screen, select S3, and then select Next, as shown in this screenshot:
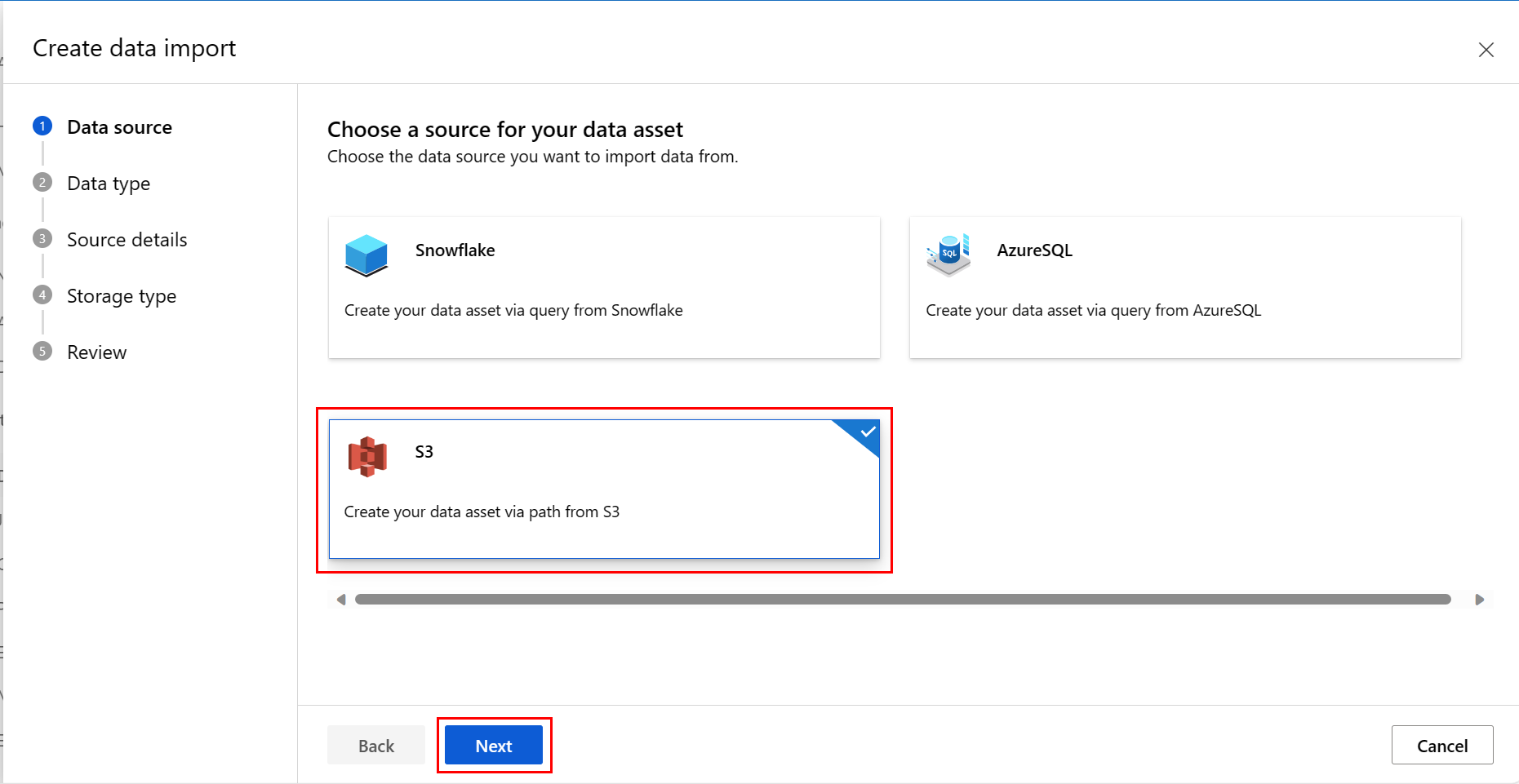
At the Data Type screen, fill in the values. The Type value defaults to Folder (uri_folder). Then select Next, as shown in this screenshot:

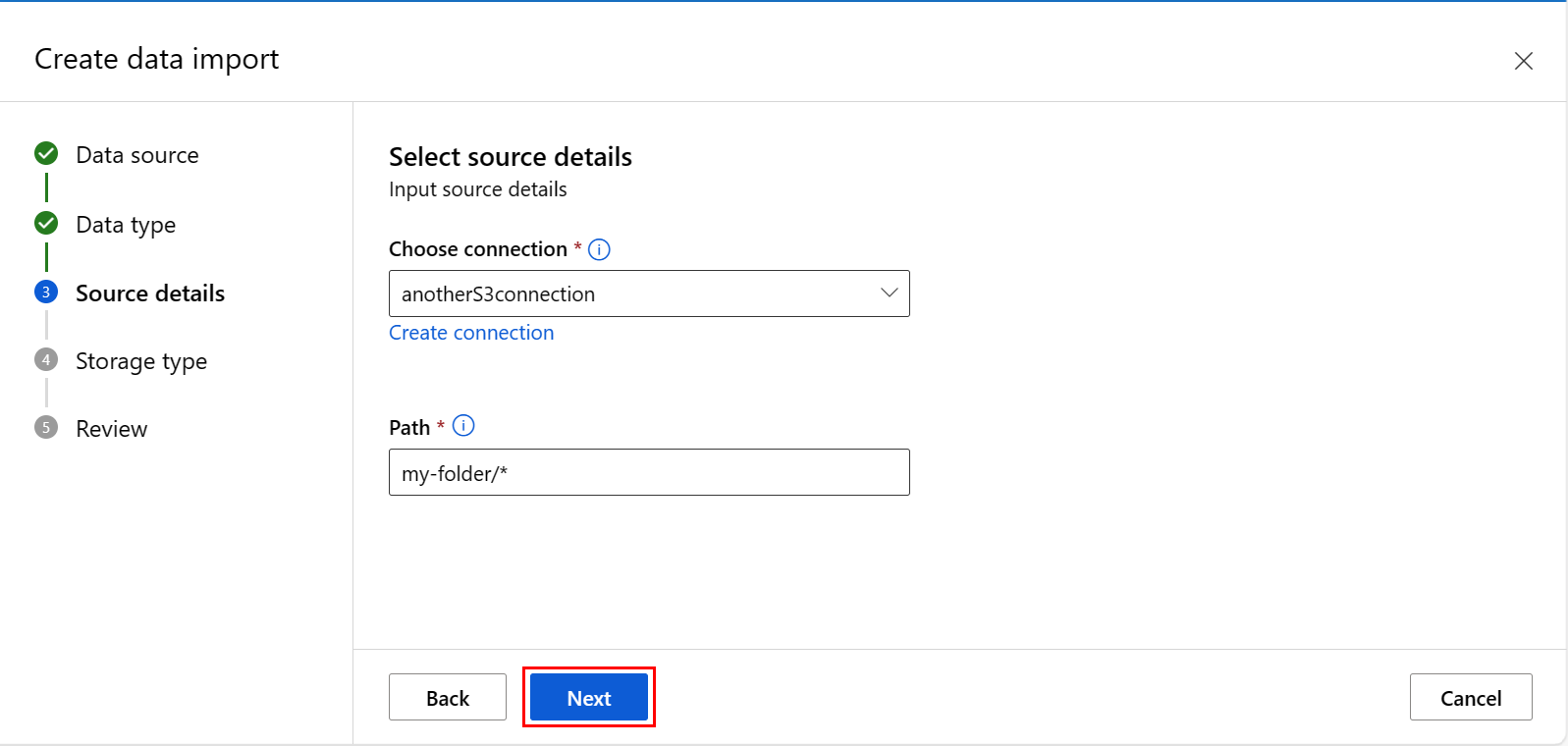
At the Create data import screen, fill in the values, and select Next, as shown in this screenshot:
Fill in the values at the Choose a datastore to output screen, and select Next, as shown in this screenshot. Workspace managed datastore is selected by default; the path is automatically assigned by the system when you choose managed datastore. If you select Workspace managed datastore, the Auto delete setting dropdown appears. It offers a data deletion time window of 30 days by default, and how to manage imported data assets explains how to change this value.
You can add a schedule. Select Add schedule as shown in this screenshot:
A new panel opens, where you can define a Recurrence schedule, or a Cron schedule. This screenshot shows the panel for a Recurrence schedule:
- Name: the unique identifier of the schedule within the workspace.
- Description: the schedule description.
- Trigger: the recurrence pattern of the schedule, which includes the following properties.
- Time zone: the trigger time calculation is based on this time zone; (UTC) Coordinated Universal Time by default.
- Recurrence or Cron expression: select recurrence to specify the recurring pattern. Under Recurrence, you can specify the recurrence frequency - by minutes, hours, days, weeks, or months.
- Start: the schedule first becomes active on this date. By default, the creation date of this schedule.
- End: the schedule will become inactive after this date. By default, it's NONE, which means that the schedule will always be active until you manually disable it.
- Tags: the selected schedule tags.
Note
Start specifies the start date and time with the timezone of the schedule. If start is omitted, the start time equals the schedule creation time. For a start time in the past, the first job runs at the next calculated run time.
As shown in the next screenshot, review your choices at the last screen of this process, and select Create. At this screen, and the other screens in this process, select Back to move to earlier screens if you'd like to change your choices of values.
The next screenshot shows the last screen of this process. Review your choices, and select Create. At this screen, and the other screens in this process, select Back to move to earlier screens to change your choices of values.
This screenshot shows the panel for a Cron schedule:
Name: the unique identifier of the schedule within the workspace.
Description: the schedule description.
Trigger: the recurrence pattern of the schedule, which includes the following properties.
Time zone: the trigger time calculation is based on this time zone; (UTC) Coordinated Universal Time by default.
Recurrence or Cron expression: select cron expression to specify the cron details.
(Required) expression uses a standard crontab expression to express a recurring schedule. A single expression is composed of five space-delimited fields:
MINUTES HOURS DAYS MONTHS DAYS-OF-WEEK
A single wildcard (*), which covers all values for the field. A *, in days, means all days of a month (which varies with month and year).
The expression: "15 16 * * 1" in the sample above means the 16:15PM on every Monday.
The next table lists the valid values for each field:
| Field |
Range |
Comment |
MINUTES |
0-59 |
- |
HOURS |
0-23 |
- |
DAYS |
- |
Not supported. The value is ignored and treated as *. |
MONTHS |
- |
Not supported. The value is ignored and treated as *. |
DAYS-OF-WEEK |
0-6 |
Zero (0) means Sunday. Names of days also accepted. |
For more information about crontab expressions, visit the Crontab Expression wiki on GitHub.
Important
DAYS and MONTH are not supported. If you pass one of these values, it will be ignored and treated as *.
- Start: the schedule first becomes active on this date. By default, the creation date of this schedule.
- End: the schedule will become inactive after this date. By default, it's NONE, which means that the schedule will always be active until you manually disable it.
- Tags: the selected schedule tags.
Note
Start specifies the start date and time with the timezone of the schedule. If start is omitted, the start time equals the schedule creation time. For a start time in the past, the first job runs at the next calculated run time.
The next screenshot shows the last screen of this process. Review your choices, and select Create. At this screen, and the other screens in this process, select Back to move to earlier screens to change your choices of values.
Check the import status of external data sources
The data import action is an asynchronous action. It can take a long time. After submission of an import data action via the CLI or SDK, the Azure Machine Learning service might need several minutes to connect to the external data source. Then, the service would start the data import, and handle data caching and registration. The time needed for a data import also depends on the size of the source data set.
The next example returns the status of the submitted data import activity. The command or method uses the "data asset" name as the input to determine the status of the data materialization.
> az ml data list-materialization-status --name <name>
from azure.ai.ml.entities import DataImport
from azure.ai.ml import MLClient
ml_client = MLClient.from_config()
ml_client.data.show_materialization_status(name="<name>")
Next steps













