Author scoring scripts for batch deployments
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Batch endpoints allow you to deploy models that perform long-running inference at scale. When deploying models, you must create and specify a scoring script (also known as a batch driver script) to indicate how to use it over the input data to create predictions. In this article, you'll learn how to use scoring scripts in model deployments for different scenarios. You'll also learn about best practices for batch endpoints.
Tip
MLflow models don't require a scoring script. It is autogenerated for you. For more information about how batch endpoints work with MLflow models, visit the Using MLflow models in batch deployments dedicated tutorial.
Warning
To deploy an Automated ML model under a batch endpoint, note that Automated ML provides a scoring script that only works for Online Endpoints. That scoring script is not designed for batch execution. Please follow these guidelines for more information about how to create a scoring script, customized for what your model does.
Understanding the scoring script
The scoring script is a Python file (.py) that specifies how to run the model, and read the input data that the batch deployment executor submits. Each model deployment provides the scoring script (along with all other required dependencies) at creation time. The scoring script usually looks like this:
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
The scoring script must contain two methods:
The init method
Use the init() method for any costly or common preparation. For example, use it to load the model into memory. The start of the entire batch job calls this function one time. The files of your model are available in a path determined by the environment variable AZUREML_MODEL_DIR. Depending on how your model was registered, its files might be contained in a folder. In the next example, the model has several files in a folder named model. For more information, visit how you can determine the folder that your model uses.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
In this example, we place the model in global variable model. To make available the assets required to perform inference on your scoring function, use global variables.
The run method
Use the run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] method to handle the scoring of each mini-batch that the batch deployment generates. This method is called once for each mini_batch generated for your input data. Batch deployments read data in batches according to how the deployment configuration.
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
The method receives a list of file paths as a parameter (mini_batch). You can use this list to iterate over and individually process each file, or to read the entire batch and process it all at once. The best option depends on your compute memory and the throughput you need to achieve. For an example that describes how to read entire batches of data at once, visit High throughput deployments.
Note
How is work distributed?
Batch deployments distribute work at the file level, which means that a folder that contains 100 files, with mini-batches of 10 files, generates 10 batches of 10 files each. Note that the sizes of the relevant files have no relevance. For files too large to process in large mini-batches, we suggest that you either split the files into smaller files to achieve a higher level of parallelism, or decrease the number of files per mini-batch. At this time, batch deployment can't account for skews in the file's size distribution.
The run() method should return a Pandas DataFrame or an array/list. Each returned output element indicates one successful run of an input element in the input mini_batch. For file or folder data assets, each returned row/element represents a single file processed. For a tabular data asset, each returned row/element represents a row in a processed file.
Important
How to write predictions?
Everything that the run() function returns will be appended in the output predictions file that the batch job generates. It is important to return the right data type from this function. Return arrays when you need to output a single prediction. Return pandas DataFrames when you need to return multiple pieces of information. For instance, for tabular data, you might want to append your predictions to the original record. Use a pandas DataFrame to do this. Although a pandas DataFrame might contain column names, the output file does not include those names.
to write predictions in a different way, you can customize outputs in batch deployments.
Warning
In the run function, don't output complex data types (or lists of complex data types) instead of pandas.DataFrame. Those outputs will be transformed to strings and they will become hard to read.
The resulting DataFrame or array is appended to the indicated output file. There's no requirement about the cardinality of the results. One file can generate 1 or many rows/elements in the output. All elements in the result DataFrame or array are written to the output file as-is (considering the output_action isn't summary_only).
Python packages for scoring
You must indicate any library that your scoring script requires to run in the environment where your batch deployment runs. For scoring scripts, environments are indicated per deployment. Usually, you indicate your requirements using a conda.yml dependencies file, which might look like this:
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
Writing predictions in a different way
By default, the batch deployment writes the model's predictions in a single file as indicated in the deployment. However, in some cases, you must write the predictions in multiple files. For instance, for partitioned input data, you would likely want to generate partitioned output as well. In those cases, you can Customize outputs in batch deployments to indicate:
- The file format (CSV, parquet, json, etc) used to write predictions
- The way data is partitioned in the output
Visit Customize outputs in batch deployments for more information about how to achieve it.
Source control of scoring scripts
It's highly advisable to place scoring scripts under source control.
Best practices for writing scoring scripts
When writing scoring scripts that handle large amounts of data, you must take into account several factors, including
- The size of each file
- The amount of data on each file
- The amount of memory required to read each file
- The amount of memory required to read an entire batch of files
- The memory footprint of the model
- The model memory footprint, when running over the input data
- The available memory in your compute
Batch deployments distribute work at the file level. This means that a folder that contains 100 files, in mini-batches of 10 files, generates 10 batches of 10 files each (regardless of the size of the files involved). For files too large to process in large mini-batches, we suggest that you split the files into smaller files, to achieve a higher level of parallelism, or that you decrease the number of files per mini-batch. At this time, batch deployment can't account for skews in the file's size distribution.
Relationship between the degree of parallelism and the scoring script
Your deployment configuration controls both the size of each mini-batch and the number of workers on each node. This becomes important when you decide whether or not to read the entire mini-batch to perform inference, to run inference file by file, or run the inference row by row (for tabular). Visit Running inference at the mini-batch, file or the row level for more information.
When running multiple workers on the same instance, you should account for the fact that memory is shared across all the workers. An increase in the number of workers per node should generally accompany a decrease in the mini-batch size, or by a change in the scoring strategy if data size and compute SKU remains the same.
Running inference at the mini-batch, file or the row level
Batch endpoints call the run() function in a scoring script once per mini-batch. However, you can decide if you want to run the inference over the entire batch, over one file at a time, or over one row at a time for tabular data.
Mini-batch level
You'll typically want to run inference over the batch all at once, to achieve high throughput in your batch scoring process. This happens if you run inference over a GPU, where you want to achieve saturation of the inference device. You might also rely on a data loader that can handle the batching itself if data doesn't fit on memory, like TensorFlow or PyTorch data loaders. In these cases, you might want to run inference on the entire batch.
Warning
Running inference at the batch level might require close control over the input data size, to correctly account for the memory requirements and to avoid out-of-memory exceptions. Whether or not you can load the entire mini-batch in memory depends on the size of the mini-batch, the size of the instances in the cluster, the number of workers on each node, and the size of the mini-batch.
Visit High throughput deployments to learn how to achieve this. This example processes an entire batch of files at a time.
File level
One of the easiest ways to perform inference is iteration over all the files in the mini-batch, and then run the model over it. In some cases, for example image processing, this might be a good idea. For tabular data, you might need to make a good estimation about the number of rows in each file. This estimate can show whether or not your model can handle the memory requirements to both load the entire data into memory and to perform inference over it. Some models (especially those models based on recurrent neural networks) unfold and present a memory footprint with a potentially nonlinear row count. For a model with high memory expense, consider running inference at the row level.
Tip
Consider breaking down files too large to read at once into multiple smaller files, to account for better parallelization.
Visit Image processing with batch deployments to learn how to do this. That example processes a file at a time.
Row level (tabular)
For models that present challenges with their input sizes, you might want to run inference at the row level. Your batch deployment still provides your scoring script with a mini-batch of files. However, you'll read one file, one row at a time. This might seem inefficient, but for some deep learning models it might be the only way to perform inference without scaling up your hardware resources.
Visit Text processing with batch deployments to learn how to do this. That example processes a row at a time.
Using models that are folders
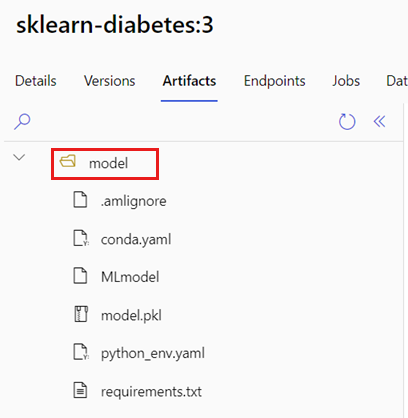
The AZUREML_MODEL_DIR environment variable contains the path to the selected model location, and the init() function typically uses it to load the model into memory. However, some models might contain their files in a folder, and you might need to account for that when loading them. You can identify the folder structure of your model as shown here:
Go to the section Models.
Select the model you want to deploy, and select the Artifacts tab.
Note the displayed folder. This folder was indicated when the model was registered.

Use this path to load the model:
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)