Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Follow this article when you want to parse the Excel files. The service supports both ".xls" and ".xlsx".
Excel format is supported for the following connectors: Amazon S3, Amazon S3 Compatible Storage, Azure Blob, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage and SFTP. It's supported as source but not sink.
Note
".xls" format isn't supported while using HTTP.
Dataset properties
For a full list of sections and properties available for defining datasets, see the Datasets article. This section provides a list of properties supported by the Excel dataset.
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to Excel. | Yes |
| location | Location settings of the file(s). Each file-based connector has its own location type and supported properties under location. |
Yes |
| sheetName | The Excel worksheet name to read data. | Specify sheetName or sheetIndex |
| sheetIndex | The Excel worksheet index to read data, starting from 0. | Specify sheetName or sheetIndex |
| range | The cell range in the given worksheet to locate the selective data, e.g.: - Not specified: reads the whole worksheet as a table from the first non-empty row and column - A3: reads a table starting from the given cell, dynamically detects all the rows below and all the columns to the right- A3:H5: reads this fixed range as a table- A3:A3: reads this single cell |
No |
| firstRowAsHeader | Specifies whether to treat the first row in the given worksheet/range as a header line with names of columns. Allowed values are true and false (default). |
No |
| nullValue | Specifies the string representation of null value. The default value is empty string. |
No |
| compression | Group of properties to configure file compression. Configure this section when you want to do compression/decompression during activity execution. | No |
| type (under compression) |
The compression codec used to read/write JSON files. Allowed values are bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy, or lz4. Default is not compressed. Note currently Copy activity doesn't support "snappy" & "lz4", and mapping data flow doesn't support "ZipDeflate", "TarGzip" and "Tar". Note when using copy activity to decompress ZipDeflate file(s) and write to file-based sink data store, files are extracted to the folder: <path specified in dataset>/<folder named as source zip file>/. |
No. |
| level (under compression) |
The compression ratio. Allowed values are Optimal or Fastest. - Fastest: The compression operation should complete as quickly as possible, even if the resulting file isn't optimally compressed. - Optimal: The compression operation should be optimally compressed, even if the operation takes a longer time to complete. For more information, see Compression Level topic. |
No |
Below is an example of Excel dataset on Azure Blob Storage:
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
Copy activity properties
For a full list of sections and properties available for defining activities, see the Pipelines article. This section provides a list of properties supported by the Excel source.
Excel as source
The following properties are supported in the copy activity *source* section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to ExcelSource. | Yes |
| storeSettings | A group of properties on how to read data from a data store. Each file-based connector has its own supported read settings under storeSettings. |
No |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
Mapping data flow properties
In mapping data flows, you can read Excel format in the following data stores: Azure Blob Storage, Azure Data Lake Storage Gen2, Amazon S3 and SFTP. You can point to Excel files either using Excel dataset or using an inline dataset.
Source properties
The below table lists the properties supported by an Excel source. You can edit these properties in the Source options tab. When using inline dataset, you'll see additional file settings, which are the same as the properties described in dataset properties section.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Wild card paths | All files matching the wildcard path will be processed. Overrides the folder and file path set in the dataset. | no | String[] | wildcardPaths |
| Partition root path | For file data that is partitioned, you can enter a partition root path in order to read partitioned folders as columns | no | String | partitionRootPath |
| List of files | Whether your source is pointing to a text file that lists files to process | no | true or false |
fileList |
| Column to store file name | Create a new column with the source file name and path | no | String | rowUrlColumn |
| After completion | Delete or move the files after processing. File path starts from the container root | no | Delete: true or false Move: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filter by last modified | Choose to filter files based upon when they were last altered | no | Timestamp | modifiedAfter modifiedBefore |
| Allow no files found | If true, an error isn't thrown if no files are found | no | true or false |
ignoreNoFilesFound |
Source example
The below image is an example of an Excel source configuration in mapping data flows using dataset mode.
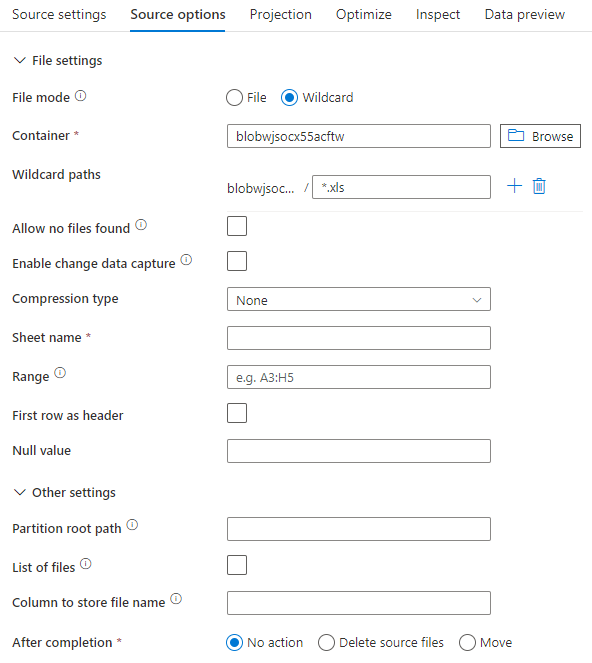
The associated data flow script is:
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
If you use inline dataset, you see the following source options in mapping data flow.
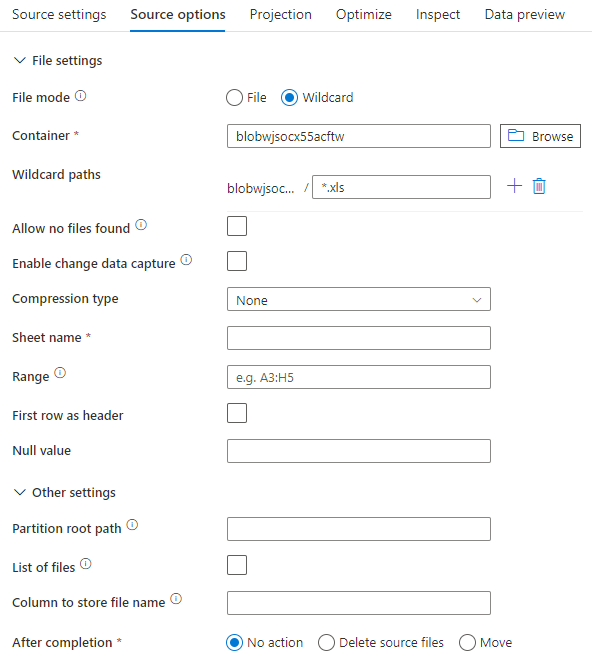
The associated data flow script is:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
Note
Mapping data flow doesn't support reading protected Excel files, as these files may contain confidentiality notices or enforce specific access restrictions that limit access to their contents.
Handling very large Excel files
The Excel connector doesn't support streaming read for the Copy activity and must load the entire file into memory before data can be read. To import schema, preview data, or refresh an Excel dataset, the data must be returned before the http request timeout (100s). For large Excel files, these operations may not finish within that timeframe, causing a timeout error. If you want to move large Excel files (>100MB) into another data store, you can use one of following options to work around this limitation:
- Use the self-hosted integration runtime (SHIR), then use the Copy activity to move the large Excel file into another data store with the SHIR.
- Split the large Excel file into several smaller ones, then use the Copy activity to move the folder containing the files.
- Use a dataflow activity to move the large Excel file into another data store. Dataflow supports streaming read for Excel and can move/transfer large files quickly.
- Manually convert the large Excel file to CSV format, then use a Copy activity to move the file.