Overview of business continuity with Azure SQL Managed Instance
Applies to: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
This article provides an overview of the business continuity and disaster recovery capabilities of Azure SQL Managed Instance, describing the options and recommendations for recovering from disruptive events that could lead to data loss or cause your instance and application to become unavailable. Learn what to do when a user or application error affects data integrity, an Azure availability zone or region has an outage, or your application requires maintenance.
Overview
Business continuity in Azure SQL Managed Instance refers to the mechanisms, policies, and procedures that enable your business to continue operating in the face of disruption by providing availability, high availability, and disaster recovery.
In most cases, SQL Managed Instance handles disruptive events that might happen in a cloud environment and keeps your applications and business processes running. However, there are some disruptive events where mitigation might take some time, such as:
- User accidentally deletes or updates a row in a table.
- Malicious attacker successfully deletes data or drops a database.
- Catastrophic natural disaster event takes down a datacenter or availability zone or region.
- Rare datacenter, availability zone or region-wide outage caused by a configuration change, software bug or hardware component failure.
Availability
Azure SQL Managed Instance comes with a core resiliency and reliability promise that protects it against software or hardware failures. Database backups are automated to protect your data from corruption or accidental deletion. As a Platform-as-a-service (PaaS), the Azure SQL Managed Instance service provides availability as an off-the-shelf feature with an industry-leading availability SLA of 99.99%.
Disaster recovery
To achieve higher availability and redundancy across regions, you can enable disaster recovery capabilities to quickly recover the instance from a catastrophic regional failure. Options for disaster recovery with Azure SQL Managed Instance are:
- Failover groups enable continuous synchronization between a primary and secondary instance. Failover groups provide read-write and read-only listener endpoints that remain unchanged so updating application connection strings after failover isn't necessary.
- Geo-restore allows you to recover from a regional outage by restoring from geo replicated backups when you can't access your database in the primary region by creating a new database on any existing instance in any Azure region.
Features that provide business continuity
For an instance, there are four major potential disruption scenarios. The following table lists SQL Managed Instance business continuity features you can use to mitigate a potential business disruption scenario:
| Business disruption scenario | Business continuity feature |
|---|---|
| Local hardware or software failures affecting the database node. | To mitigate local hardware and software failures, SQL Managed Instance includes an availability architecture, which guarantees automatic recovery from these failures with up to 99.99% availability SLA. |
| Data corruption or deletion typically caused by an application bug or human error. Such failures are application-specific and typically can't be detected by the service. | To protect your business from data loss, SQL Managed Instance automatically creates full database backups weekly, differential database backups every 12 or 24 hours, and transaction log backups every 5 - 10 minutes. By default, backups are stored in geo-redundant storage for seven days, and support a configurable backup retention period for point-in-time restore of up to 35 days. You can restore a deleted database to the point at which it was deleted if the instance hasn't been deleted, or if you've configured long-term retention. |
| Rare region outage impacting all availability zones and the datacenters comprising it, possibly caused by catastrophic natural disaster event. | To mitigate a region-wide outage, enable disaster recovery using one of the options: - Continuous data synchronization with failover groups to replicas in a secondary region used for failover. - Setting backup storage redundancy to geo-redundant backup storage to use geo-restore. |
RTO and RPO
As you develop your business continuity plan, understand the maximum acceptable time before the application fully recovers after the disruptive event. The time required for an application to fully recover is known as the Recovery Time Objective (RTO). Also understand the maximum period of recent data updates (time interval) the application can tolerate losing when recovering from an unplanned disruptive event. The potential data loss is known as Recovery Point Objective (RPO).
The following table compares RPO and RTO of each business continuity option:
| Business continuity option | RTO (downtime) | RPO (data loss) |
|---|---|---|
| High Availability (Using zone redundancy) |
Typically less than 30 seconds | 0 |
| Disaster Recovery (Using failover groups with customer managed failover policy) |
Typically less than 60 seconds | Equal to or greater than 0 (Depends on data changes before the disruptive event that haven't been replicated) |
| Disaster Recovery (Using geo-restore) |
12 hours | 1 hour |
Recover a database within the same Azure region
You can use automatic database backups to restore a database to a point in time in the past. This way you can recover from data corruptions caused by human errors. Point-in-time restore (PITR) allows you to create a new database to the same instance, or a different instance, that represents the state of data prior to the corrupting event. The restore operation is a size of data operation that also depends on the current workload of the target instance. It might take longer to recover a very large or very active database. For more information about recovery time, see database recovery time.
If the maximum supported backup retention period for point-in-time restore (PITR) isn't sufficient for your application, you can extend it by configuring a long-term retention (LTR) policy for the database(s). For more information, see Long-term backup retention.
Recover a database to an existing instance
Although rare, an Azure datacenter can have an outage. When an outage occurs, it causes a business disruption that might only last a few minutes or might last for hours.
- One option is to wait for your instance to come back online when the datacenter outage is over. This works for applications that can afford to have their database offline. For example, a development project or free trial you don't need to work on constantly. When a datacenter has an outage, you don't know how long the outage might last, so this option only works if you don't need your database for some time.
- If you're using geo-redundant (GRS) storage, another option is to restore a database to any SQL managed instance in any Azure region using geo-redundant database backups (geo-restore). Geo-restore uses a geo-redundant backup as its source and can be used to recover a database to the last available point in time, even if the database or datacenter is inaccessible due to an outage. The available backup can be found in the paired region.
- Finally, you can quickly recover from an outage if you've configured a geo-secondary using a failover group for your instance, using either customer (recommended) or Azure-managed failover. While the failover itself takes only a few seconds, the service takes at least 1 hour to activate a Azure-managed geo-failover, if configured. This is necessary to ensure the failover is justified by the scale of the outage. Also, the failover might result in the loss of recently changed data due to the nature of asynchronous replication between the paired regions.
As you develop your business continuity plan, you need to understand the maximum acceptable time before the application fully recovers after the disruptive event. The time required for application to fully recover is known as Recovery Time Objective (RTO). You also need to understand the maximum period of recent data updates (time interval) the application can tolerate losing when recovering from an unplanned disruptive event. The potential data loss is known as Recovery Point Objective (RPO).
Different recovery methods offer different levels of RPO and RTO. You can choose a specific recovery method, or use a combination of methods to achieve full application recovery.
Use failover groups if your application meets any of these criteria:
- Is mission critical.
- Has a service level agreement (SLA) that doesn't allow for 12 hours or more of downtime.
- Downtime might result in financial liability.
- Has a high rate of data change and 1 hour of data loss isn't acceptable.
- The additional cost of active geo-replication is lower than the potential financial liability and associated loss of business.
You might choose to use a combination of database backups and failover groups depending upon your application requirements.
The following sections provide an overview of the steps to recover using either database backups or failover groups.
Prepare for an outage
Regardless of the business continuity feature you use, you must:
- Identify and prepare the target instance, including network IP firewall rules, logins, and
masterdatabase level permissions. - Determine how to redirect clients and client applications to the new instance
- Document other dependencies, such as auditing settings and alerts
If you don't prepare properly, bringing your applications online after a failover or a database recovery takes additional time, and likely also requires troubleshooting at a time of stress - a bad combination.
Fail over to a geo-replicated secondary instance
If you're using failover groups as your recovery mechanism, you can configure an automatic failover policy. Once initiated, the failover causes the secondary instance to become the new primary, ready to record new transactions and respond to queries - with minimal data loss for the data not yet replicated.
Note
When the datacenter comes back online the old primary automatically reconnects to the new primary to become the secondary instance. If you need to relocate the primary back to the original region, you can initiate a planned failover manually (failback).
Perform a geo-restore
If you're using automated backups with geo-redundant storage (the default storage option when you create your instance), you can recover the database using geo-restore. Recovery usually takes place within 12 hours - with data loss of up to one hour determined by when the last log backup was taken and replicated. Until the recovery completes, the database is unable to record any transactions or respond to any queries. Note, geo-restore only restores the database to the last available point in time.
Note
If the datacenter comes back online before you switch your application over to the recovered database, you can cancel the recovery.
Perform post failover / recovery tasks
After recovery from either recovery mechanism, you must perform the following additional tasks before your users and applications are back up and running:
- Redirect clients and client applications to the new instance and restored database.
- Ensure appropriate network IP firewall rules are in place for users to connect.
- Ensure appropriate logins and
masterdatabase-level permissions are in place (or use contained users). - Configure auditing, as appropriate.
- Configure alerts, as appropriate.
Note
If you are using a failover group and connect to the instance using the read-write listener, the redirection after failover will happen automatically and transparently to the application.
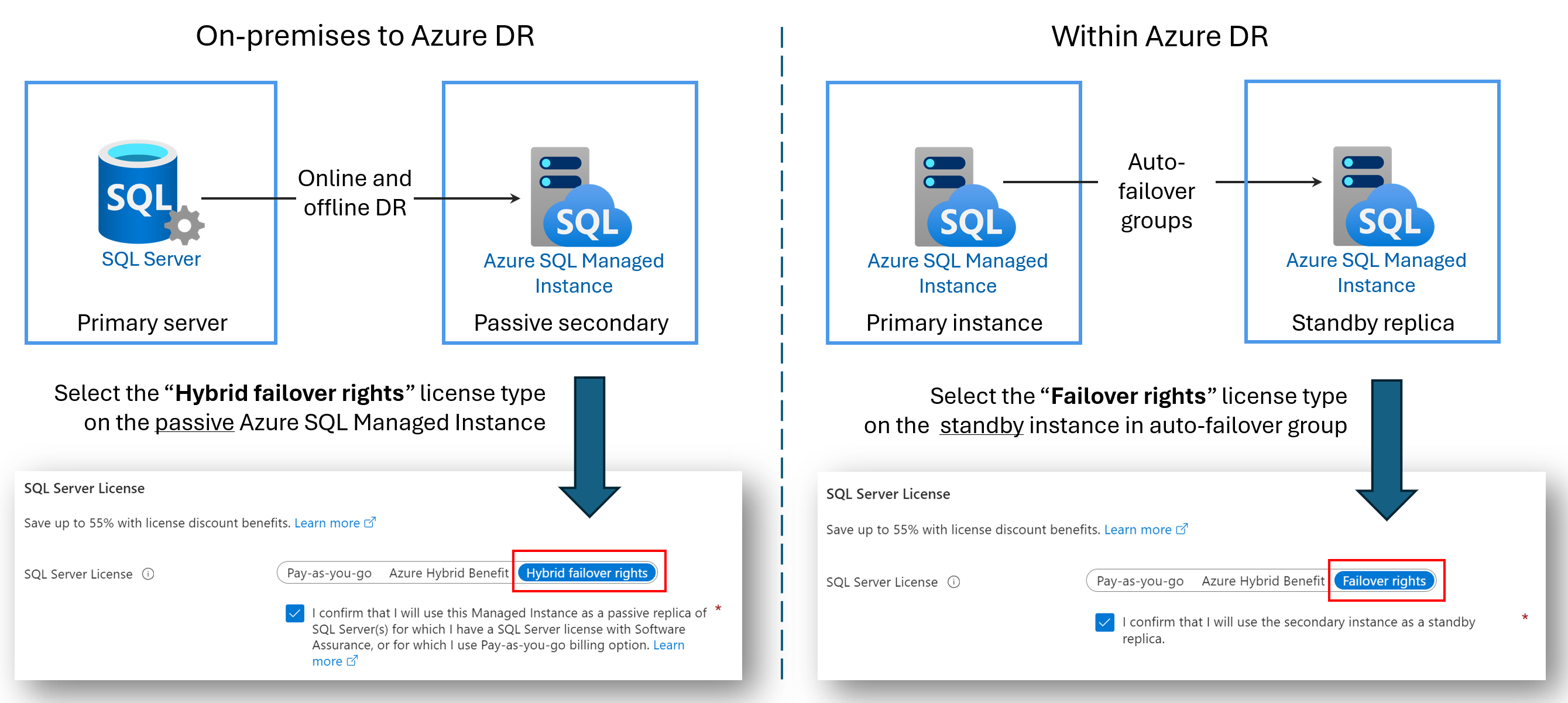
License-free DR replicas
You can save on licensing costs by configuring a secondary Azure SQL Managed Instance for only disaster recovery (DR). This benefit is available if you're using a failover group between two SQL managed instances, or you've configured a hybrid link between SQL Server and Azure SQL Managed Instance. As long as the secondary instance doesn't have any read or write workloads on it and is only a passive DR standby, you aren't charged for the vCore licensing costs used by the secondary instance.
When you designate a secondary instance for only disaster recovery, and no read or write workloads are running on the instance, Azure provides you with the number of vCores that are licensed to the primary instance at no extra charge under the failover rights benefit. You're still billed for the compute and storage that the secondary instance uses. For precise terms and conditions of the Hybrid failover rights benefit, see the SQL Server licensing terms online in the "SQL Server � Fail-over Rights" section.
The name for the benefit depends on your scenario:
- Hybrid failover rights for a passive replica: When you configure a link between SQL Server and Azure SQL Managed Instance, you can use the Hybrid failover rights benefit to save on vCore licensing costs for the passive secondary replica.
- Failover rights for a standby replica: When you configure a failover group between two managed instances, you can use the Failover rights benefit to save on vCore licensing costs for the standby secondary replica.
The following diagram demonstrates the benefit for each scenario:
Next steps
To learn more about business continuity features, see Automated backups, and failover groups. For disaster recovery, see recover a database.