Document Intelligence layout model
This content applies to: ![]() v2.1
v2.1
Document Intelligence layout model is an advanced machine-learning based document analysis API available in the Document Intelligence cloud. It enables you to take documents in various formats and return structured data representations of the documents. It combines an enhanced version of our powerful Optical Character Recognition (OCR) capabilities with deep learning models to extract text, tables, selection marks, and document structure.
Document layout analysis
Document structure layout analysis is the process of analyzing a document to extract regions of interest and their inter-relationships. The goal is to extract text and structural elements from the page to build better semantic understanding models. There are two types of roles in a document layout:
- Geometric roles: Text, tables, figures, and selection marks are examples of geometric roles.
- Logical roles: Titles, headings, and footers are examples of logical roles of texts.
The following illustration shows the typical components in an image of a sample page.

Development options
Document Intelligence v3.1 supports the following tools, applications, and libraries:
| Feature | Resources | Model ID |
|---|---|---|
| Layout model | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
Document Intelligence v3.0 supports the following tools, applications, and libraries:
| Feature | Resources | Model ID |
|---|---|---|
| Layout model | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
Document Intelligence v2.1 supports the following tools, applications, and libraries:
| Feature | Resources |
|---|---|
| Layout model | • Document Intelligence labeling tool • REST API • Client-library SDK • Document Intelligence Docker container |
Input requirements
Supported file formats:
Model PDF Image: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLRead ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) General Document ✔ ✔ Prebuilt ✔ ✔ Custom extraction ✔ ✔ Custom classification ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) For best results, provide one clear photo or high-quality scan per document.
For PDF and TIFF, up to 2,000 pages can be processed (with a free tier subscription, only the first two pages are processed).
The file size for analyzing documents is 500 MB for paid (S0) tier and
4MB for free (F0) tier.Image dimensions must be between 50 pixels x 50 pixels and 10,000 pixels x 10,000 pixels.
If your PDFs are password-locked, you must remove the lock before submission.
The minimum height of the text to be extracted is 12 pixels for a 1024 x 768 pixel image. This dimension corresponds to about
8point text at 150 dots per inch (DPI).For custom model training, the maximum number of pages for training data is 500 for the custom template model and 50,000 for the custom neural model.
For custom extraction model training, the total size of training data is 50 MB for template model and
1GB for the neural model.For custom classification model training, the total size of training data is
1GB with a maximum of 10,000 pages. For 2024-07-31-preview and later, the total size of training data is2GB with a maximum of 10,000 pages.
- Supported file formats: JPEG, PNG, PDF, and TIFF.
- Supported number of pages: For PDF and TIFF, up to 2,000 pages are processed. For free tier subscribers, only the first two pages are processed.
- Supported file size: the file size must be less than 50 MB and dimensions at least 50 x 50 pixels and at most 10,000 x 10,000 pixels.
Get started with Layout model
See how data, including text, tables, table headers, selection marks, and structure information is extracted from documents using Document Intelligence. You need the following resources:
An Azure subscription—you can create one for trial
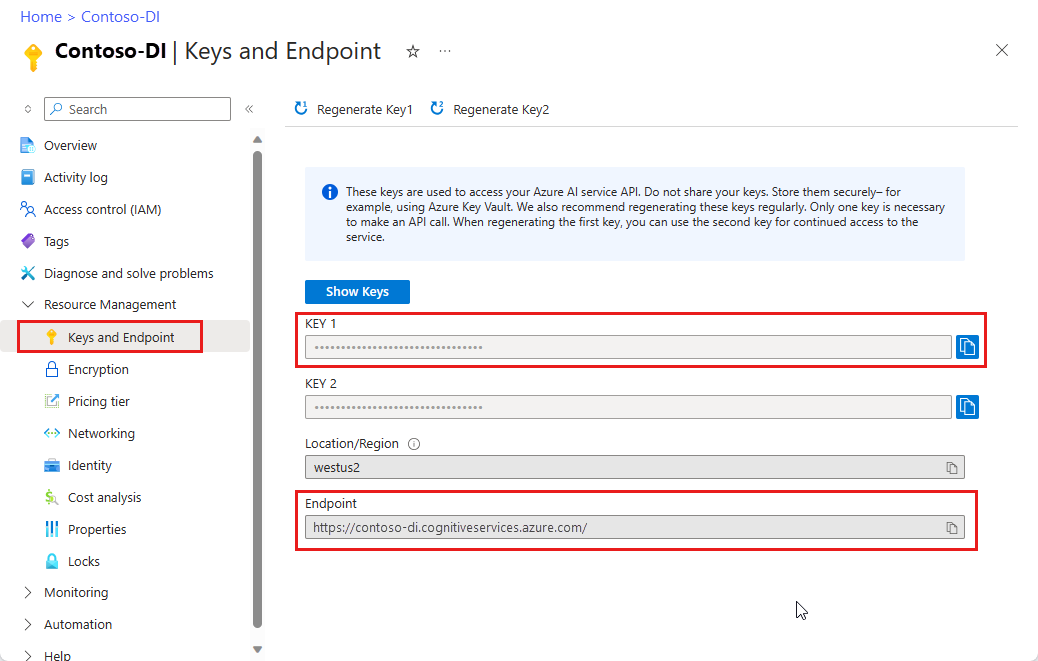
A Document Intelligence instance in the Azure portal. You can use the free pricing tier (
F0) to try the service. After your resource deploys, select Go to resource to get your key and endpoint.
Note
Document Intelligence Studio is available with v3.0 APIs and later versions.
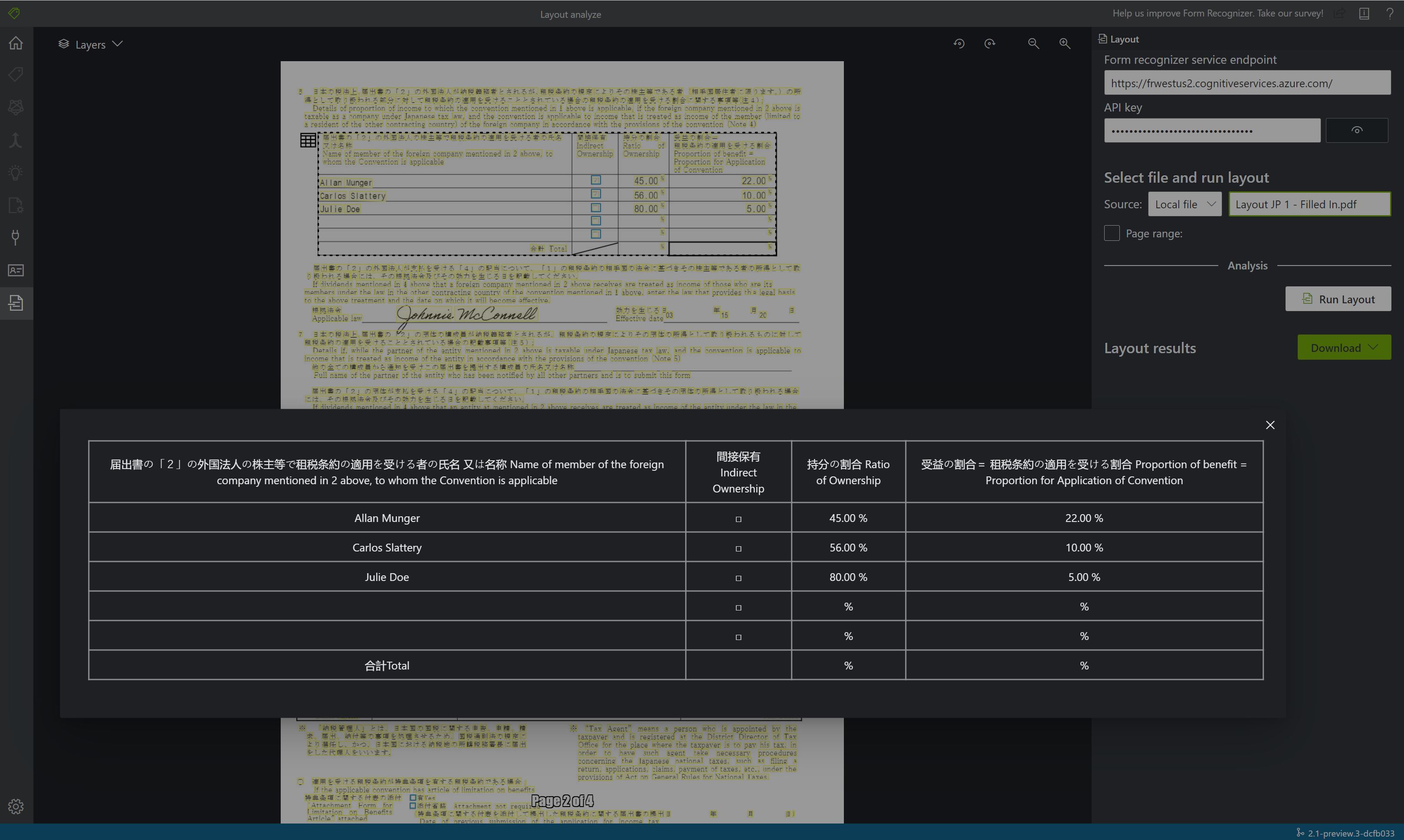
Sample document processed with Document Intelligence Studio
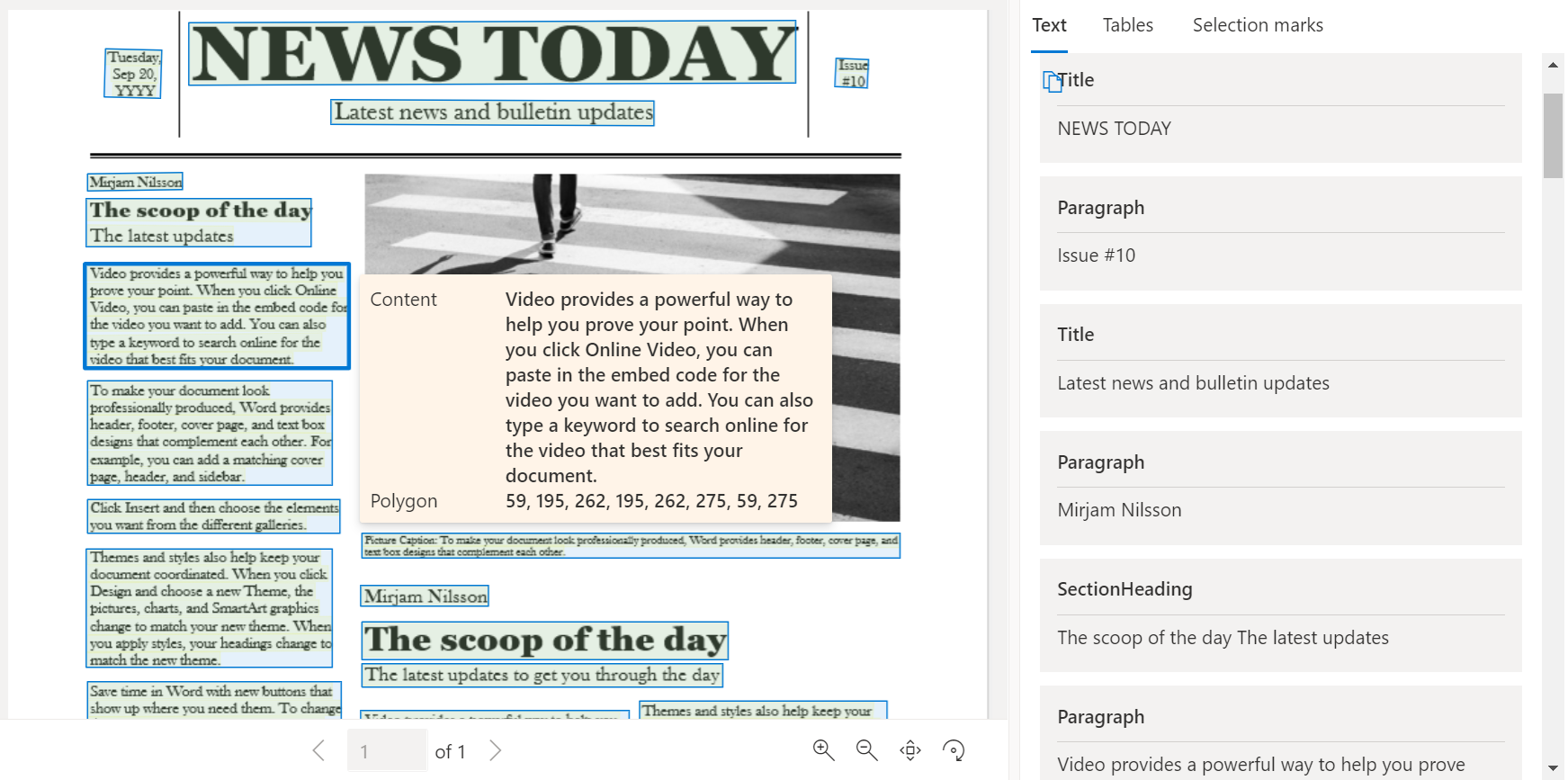
On the Document Intelligence Studio home page, select Layout.
You can analyze the sample document or upload your own files.
Select the Run analysis button and, if necessary, configure the Analyze options:

Document Intelligence Sample Labeling tool
Navigate to the Document Intelligence sample tool.
On the sample tool home page, select Use Layout to get text, tables and selection marks.
In the Document Intelligence service endpoint field, paste the endpoint that you obtained with your Document Intelligence subscription.
In the key field, paste the key you obtained from your Document Intelligence resource.
In the Source field, select URL from the dropdown menu You can use our sample document:
Select the Fetch button.
Select Run Layout. The Document Intelligence Sample Labeling tool calls the
Analyze LayoutAPI to analyze the document.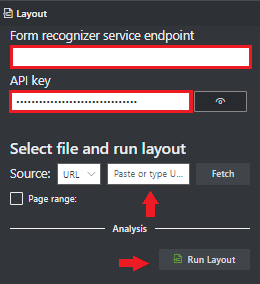
View the results - see the highlighted extracted text, detected selection marks, and detected tables.
{kind=link}
Supported languages and locales
See our Language Support—document analysis models page for a complete list of supported languages.
Document Intelligence v2.1 supports the following tools, applications, and libraries:
| Feature | Resources |
|---|---|
| Layout API |
Data extraction
The layout model extracts text, selection marks, tables, paragraphs, and paragraph types (roles) from your documents.
Note
Versions 2024-02-29-preview, 2023-10-31-preview, and later support Microsoft office (DOCX, XLSX, PPTX) and HTML files. The following features are not supported:
- There are no angle, width/height and unit with each page object.
- For each object detected, there is no bounding polygon or bounding region.
- Page range (
pages) is not supported as a parameter. - No
linesobject.
Pages
The pages collection is a list of pages within the document. Each page is represented sequentially within the document and includes the orientation angle indicating if the page is rotated and the width and height (dimensions in pixels). The page units in the model output are computed as shown:
| File format | Computed page unit | Total pages |
|---|---|---|
| Images (JPEG/JPG, PNG, BMP, HEIF) | Each image = 1 page unit | Total images |
| Each page in the PDF = 1 page unit | Total pages in the PDF | |
| TIFF | Each image in the TIFF = 1 page unit | Total images in the TIFF |
| Word (DOCX) | Up to 3,000 characters = 1 page unit, embedded or linked images not supported | Total pages of up to 3,000 characters each |
| Excel (XLSX) | Each worksheet = 1 page unit, embedded or linked images not supported | Total worksheets |
| PowerPoint (PPTX) | Each slide = 1 page unit, embedded or linked images not supported | Total slides |
| HTML | Up to 3,000 characters = 1 page unit, embedded or linked images not supported | Total pages of up to 3,000 characters each |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Extract selected pages from documents
For large multi-page documents, use the pages query parameter to indicate specific page numbers or page ranges for text extraction.
Paragraphs
The Layout model extracts all identified blocks of text in the paragraphs collection as a top level object under analyzeResults. Each entry in this collection represents a text block and includes the extracted text ascontentand the bounding polygon coordinates. The span information points to the text fragment within the top level content property that contains the full text from the document.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Paragraph roles
The new machine-learning based page object detection extracts logical roles like titles, section headings, page headers, page footers, and more. The Document Intelligence Layout model assigns certain text blocks in the paragraphs collection with their specialized role or type predicted by the model. It's best to use paragraph roles with unstructured documents to help understand the layout of the extracted content for a richer semantic analysis. The following paragraph roles are supported:
| Predicted role | Description | Supported file types |
|---|---|---|
title |
The main headings in the page | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
One or more subheadings on the page | pdf, image, docx, xlsx, html |
footnote |
Text near the bottom of the page | pdf, image |
pageHeader |
Text near the top edge of the page | pdf, image, docx |
pageFooter |
Text near the bottom edge of the page | pdf, image, docx, pptx, html |
pageNumber |
Page number | pdf, image |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Text, lines, and words
The document layout model in Document Intelligence extracts print and handwritten style text as lines and words. The styles collection includes any handwritten style for lines if detected along with the spans pointing to the associated text. This feature applies to supported handwritten languages.
For Microsoft Word, Excel, PowerPoint, and HTML, Document Intelligence versions 2024-02-29-preview and 2023-10-31-preview Layout model extract all embedded text as is. Texts are extracted as words and paragraphs. Embedded images aren't supported.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Handwritten style for text lines
The response includes classifying whether each text line is of handwriting style or not, along with a confidence score. For more information. See Handwritten language support. The following example shows an example JSON snippet.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
If you enable the font/style addon capability, you also get the font/style result as part of the styles object.
Selection marks
The Layout model also extracts selection marks from documents. Extracted selection marks appear within the pages collection for each page. They include the bounding polygon, confidence, and selection state (selected/unselected). The text representation (that is, :selected: and :unselected) is also included as the starting index (offset) and length that references the top level content property that contains the full text from the document.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
# Analyze selection marks.
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
Tables
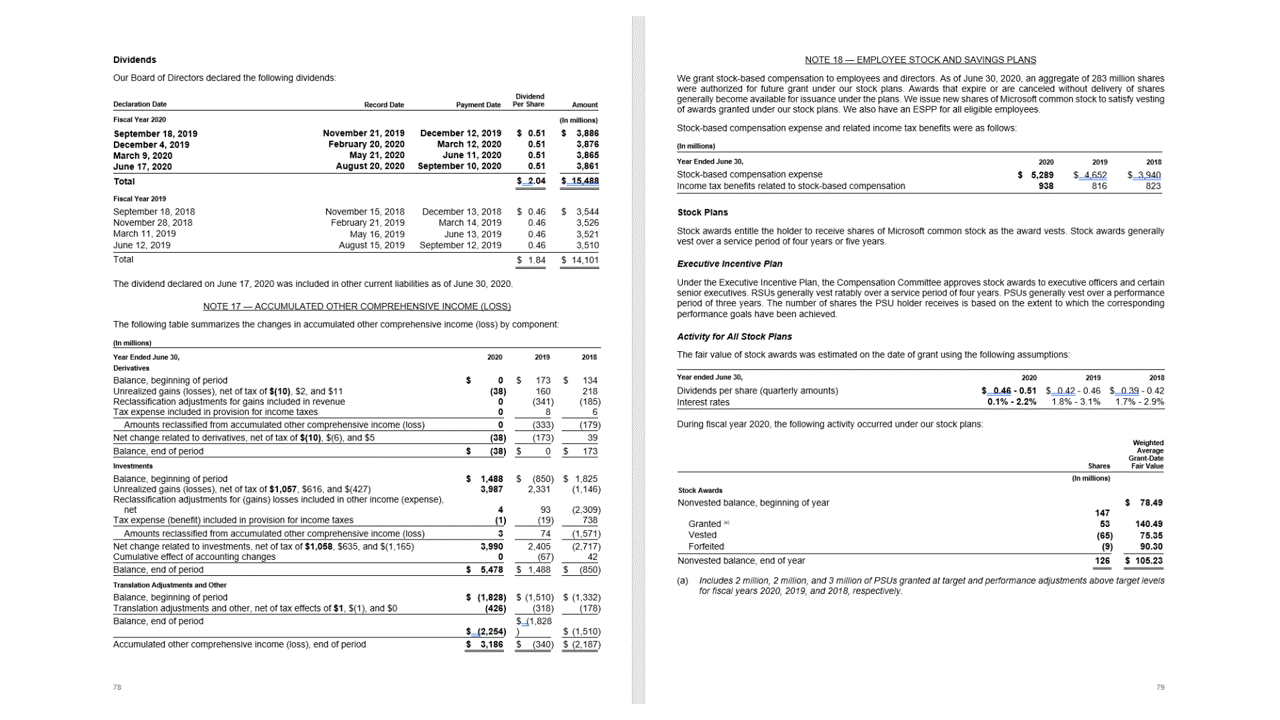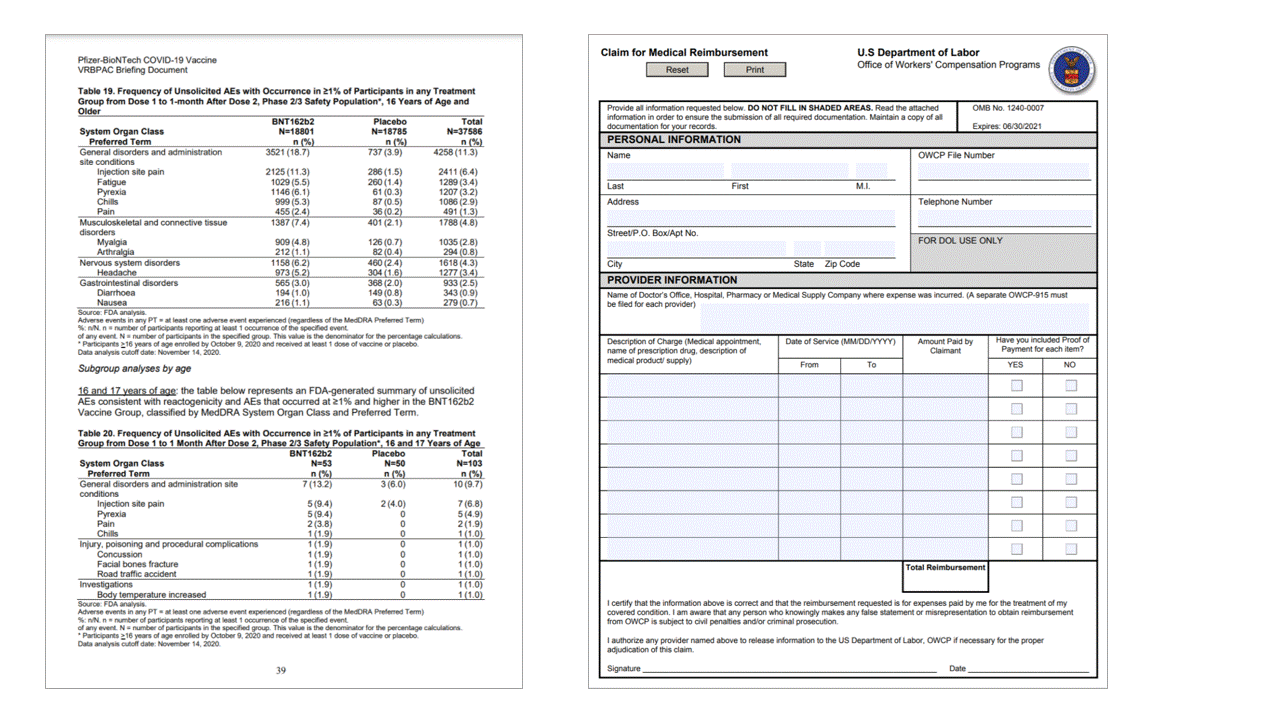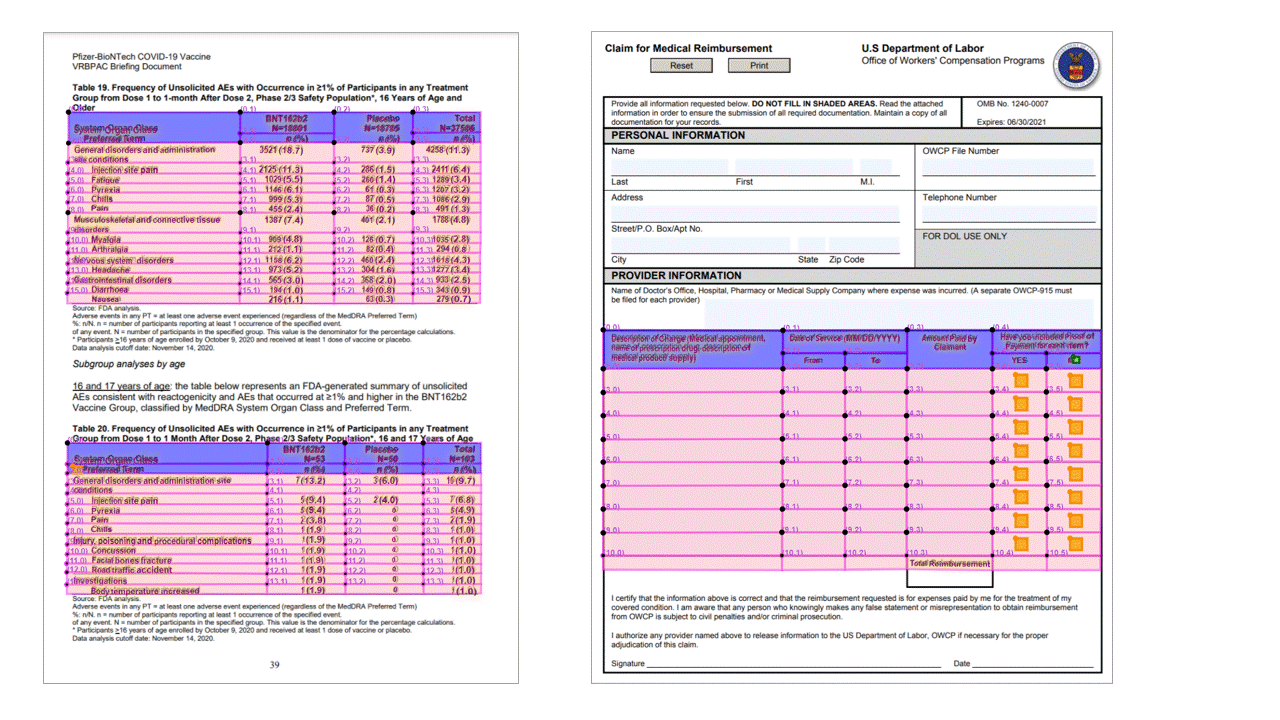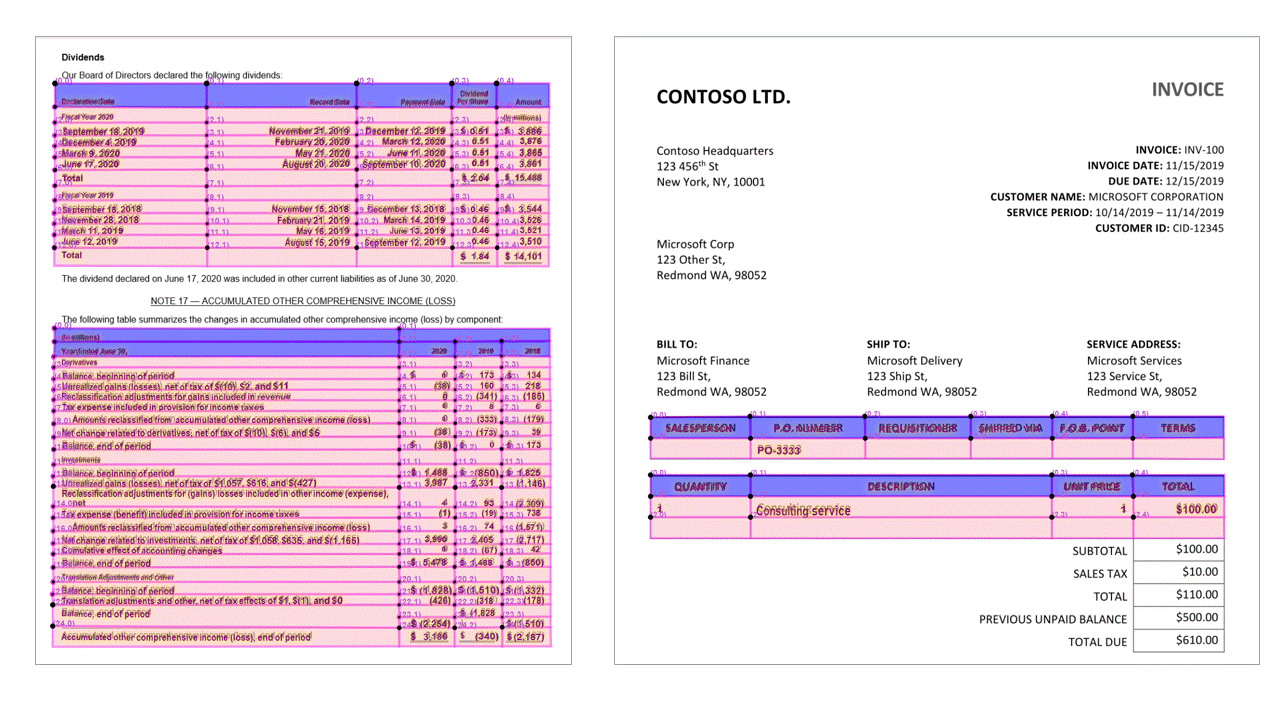
Extracting tables is a key requirement for processing documents containing large volumes of data typically formatted as tables. The Layout model extracts tables in the pageResults section of the JSON output. Extracted table information includes the number of columns and rows, row span, and column span. Each cell with its bounding polygon is output along with information whether the area is recognized as a columnHeader or not. The model supports extracting tables that are rotated. Each table cell contains the row and column index and bounding polygon coordinates. For the cell text, the model outputs the span information containing the starting index (offset). The model also outputs the length within the top-level content that contains the full text from the document.
Here are a few factors to consider when using the Document Intelligence bale extraction capability:
Is the data that you want to extract presented as a table, and is the table structure meaningful?
Can the data fit in a two-dimensional grid if the data isn't in a table format?
Do your tables span multiple pages? If so, to avoid having to label all the pages, split the PDF into pages before sending it to Document Intelligence. After the analysis, post-process the pages to a single table.
Refer to Tabular fields if you're creating custom models. Dynamic tables have a variable number of rows for each column. Fixed tables have a constant number of rows for each column.
Note
- Table analysis is not supported if the input file is XLSX.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
# Analyze tables.
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Annotations (available only in 2023-02-28-preview API.)
The Layout model extracts annotations in documents, such as checks and crosses. The response includes the kind of annotation, along with a confidence score and bounding polygon.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Natural reading order output (Latin only)
You can specify the order in which the text lines are output with the readingOrder query parameter. Use natural for a more human-friendly reading order output as shown in the following example. This feature is only supported for Latin languages.

Select page numbers or ranges for text extraction
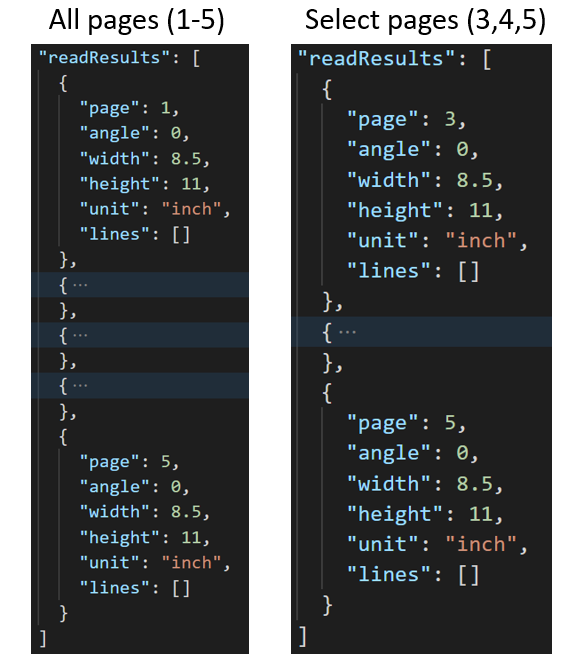
For large multi-page documents, use the pages query parameter to indicate specific page numbers or page ranges for text extraction. The following example shows a document with 10 pages, with text extracted for both cases - all pages (1-10) and selected pages (3-6).
The Get Analyze Layout Result operation
The second step is to call the Get Analyze Layout Result operation. This operation takes as input the Result ID the Analyze Layout operation created. It returns a JSON response that contains a status field with the following possible values.
| Field | Type | Possible values |
|---|---|---|
| status | string | notStarted: The analysis operation isn't started.running: The analysis operation is in progress.failed: The analysis operation failed.succeeded: The analysis operation succeeded. |
Call this operation iteratively until it returns the succeeded value. To avoid exceeding the requests per second (RPS) rate, use an interval of 3 to 5 seconds.
When the status field has the succeeded value, the JSON response includes the extracted layout, text, tables, and selection marks. The extracted data includes extracted text lines and words, bounding boxes, text appearance with handwritten indication, tables, and selection marks with selected/unselected indicated.
Handwritten classification for text lines (Latin only)
The response includes classifying whether each text line is of handwriting style or not, along with a confidence score. This feature is only supported for Latin languages. The following example shows the handwritten classification for the text in the image.

Sample JSON output
The response to the Get Analyze Layout Result operation is a structured representation of the document with all the information extracted. See here for a sample document file and its structured output sample layout output.
The JSON output has two parts:
readResultsnode contains all of the recognized text and selection mark. The text presentation hierarchy is page, then line, then individual words.pageResultsnode contains the tables and cells extracted with their bounding boxes, confidence, and a reference to the lines and words in "readResults" field.
Example Output
Text
Layout API extracts text from documents and images with multiple text angles and colors. It accepts photos of documents, faxes, printed and/or handwritten (English only) text, and mixed modes. Text is extracted with information provided on lines, words, bounding boxes, confidence scores, and style (handwritten or other). All the text information is included in the readResults section of the JSON output.
Tables with headers
Layout API extracts tables in the pageResults section of the JSON output. Documents can be scanned, photographed, or digitized. Tables can be complex with merged cells or columns, with or without borders, and with odd angles. Extracted table information includes the number of columns and rows, row span, and column span. Each cell with its bounding box is output along with whether the area is recognized as part of a header or not. The model predicted header cells can span multiple rows and aren't necessarily the first rows in a table. They also work with rotated tables. Each table cell also includes the full text with references to the individual words in the readResults section.
Selection marks
Layout API also extracts selection marks from documents. Extracted selection marks include the bounding box, confidence, and state (selected/unselected). Selection mark information is extracted in the readResults section of the JSON output.
Migration guide
- Follow our Document Intelligence v3.1 migration guide to learn how to use the v3.1 version in your applications and workflows.
Next steps
Learn how to process your own forms and documents with the Document Intelligence Studio.
Complete a Document Intelligence quickstart and get started creating a document processing app in the development language of your choice.
Learn how to process your own forms and documents with the Document Intelligence Sample Labeling tool.
Complete a Document Intelligence quickstart and get started creating a document processing app in the development language of your choice.